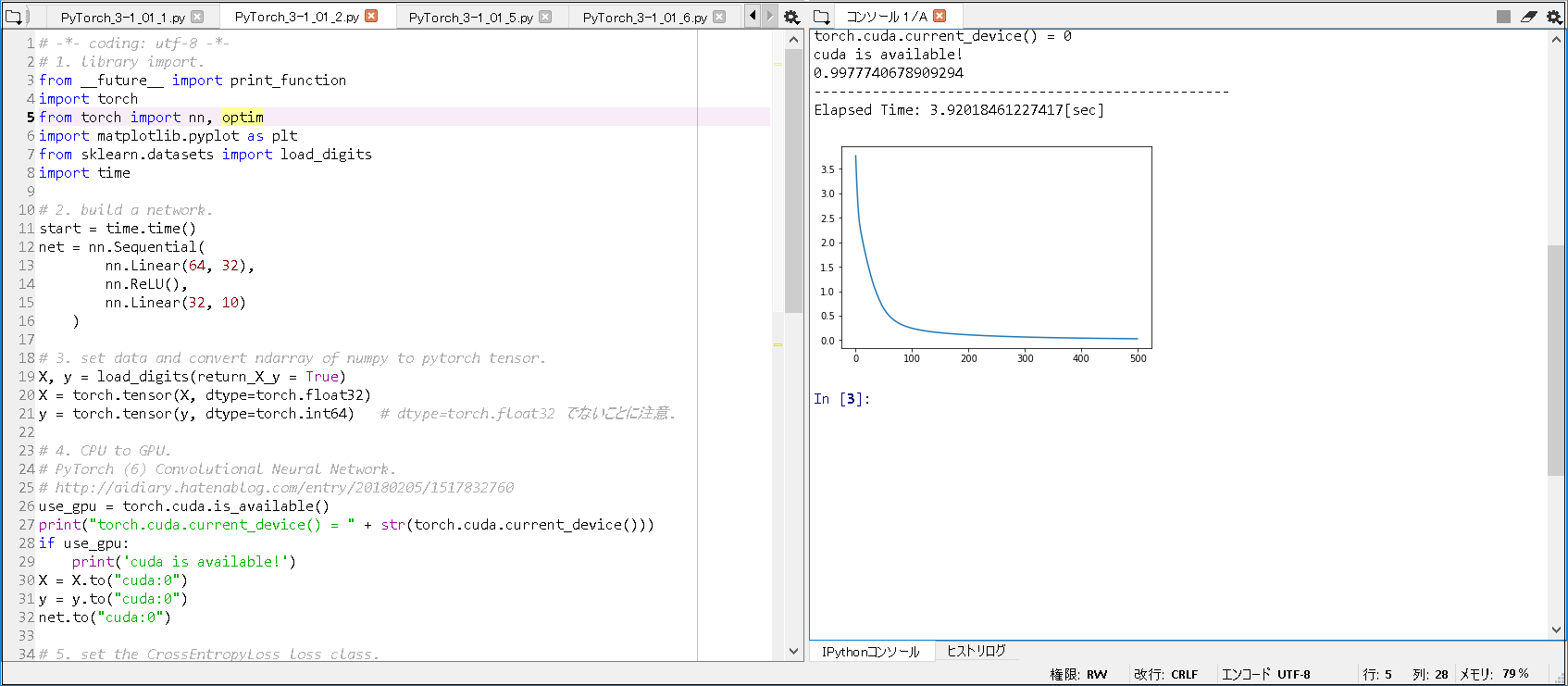
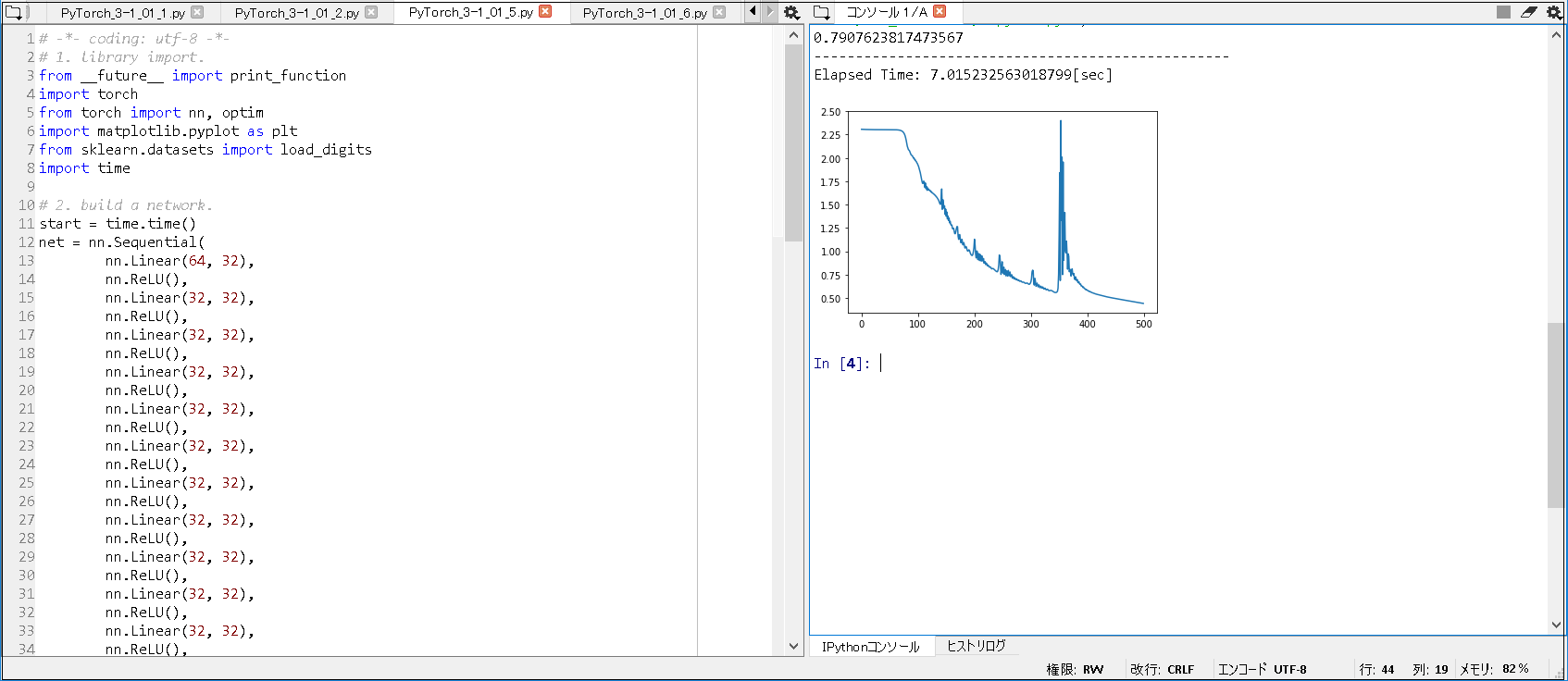
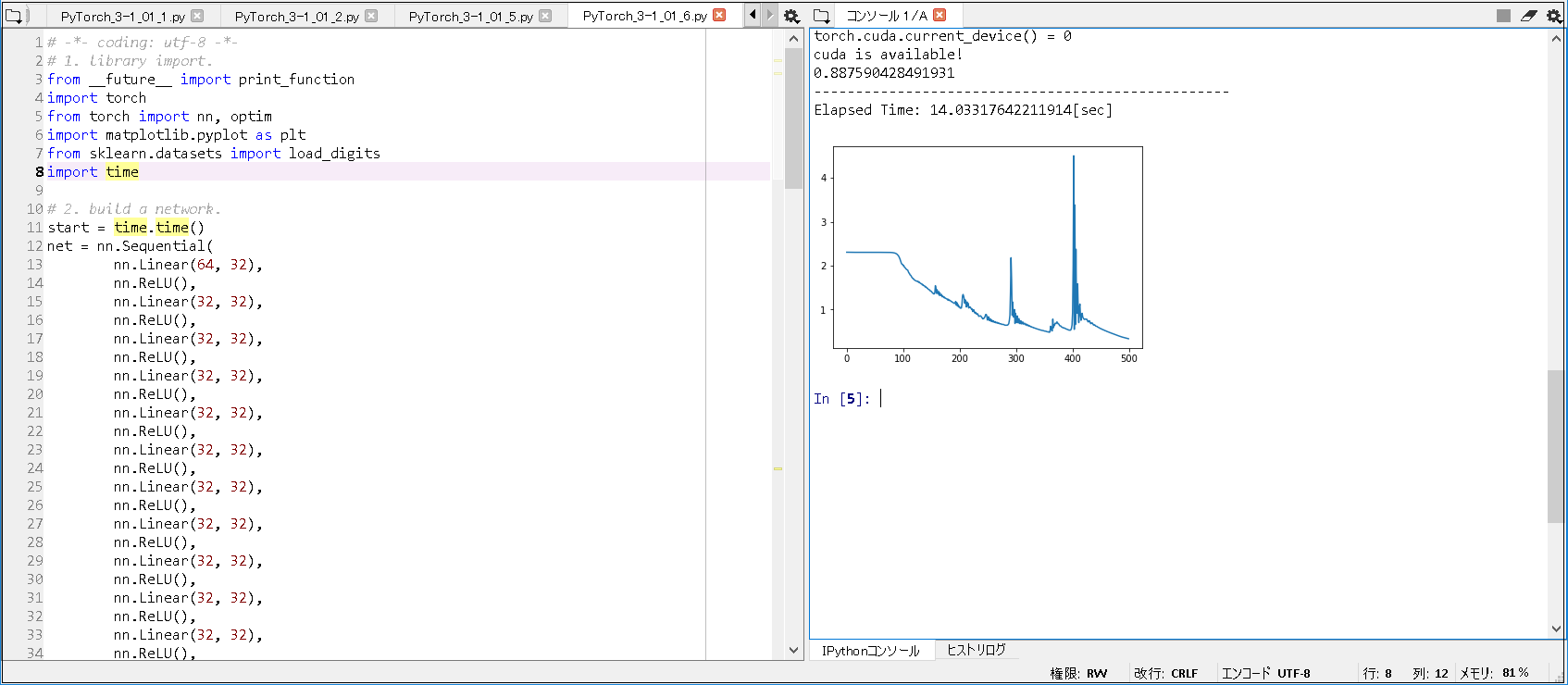
1. 環境は、Window 10 Home (64bit) 上で行った。
2. Anaconda3 (64bit) – Spyder上で、動作確認を行った。
3. python の バージョンは、python 3.6.5 である。
4. pytorch の バージョンは、pytorch 0.4.1 である。
5. GPU は, NVIDIA社 の GeForce GTX 1050 である。
6. CPU は, Intel社 の Core(TM) i7-7700HQ である。
今回確認した内容は、現場で使える! PyTorch開発入門 深層学習モデルの作成とアプリケーションへの実装 (AI & TECHNOLOGY) の 4.2.2 CNNの構築と学習(P.067 – P.071) である。
Fashion-MNIST を 使った, CNN の 画像分類 について書かれていたので, 少し動作確認を行った.
また, tqdm の使い方も確認できた.
※プログラムの詳細は、書籍を参考(P.067 – P.071)にして下さい。
■Fashion-MNISTの学習(GPU版).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
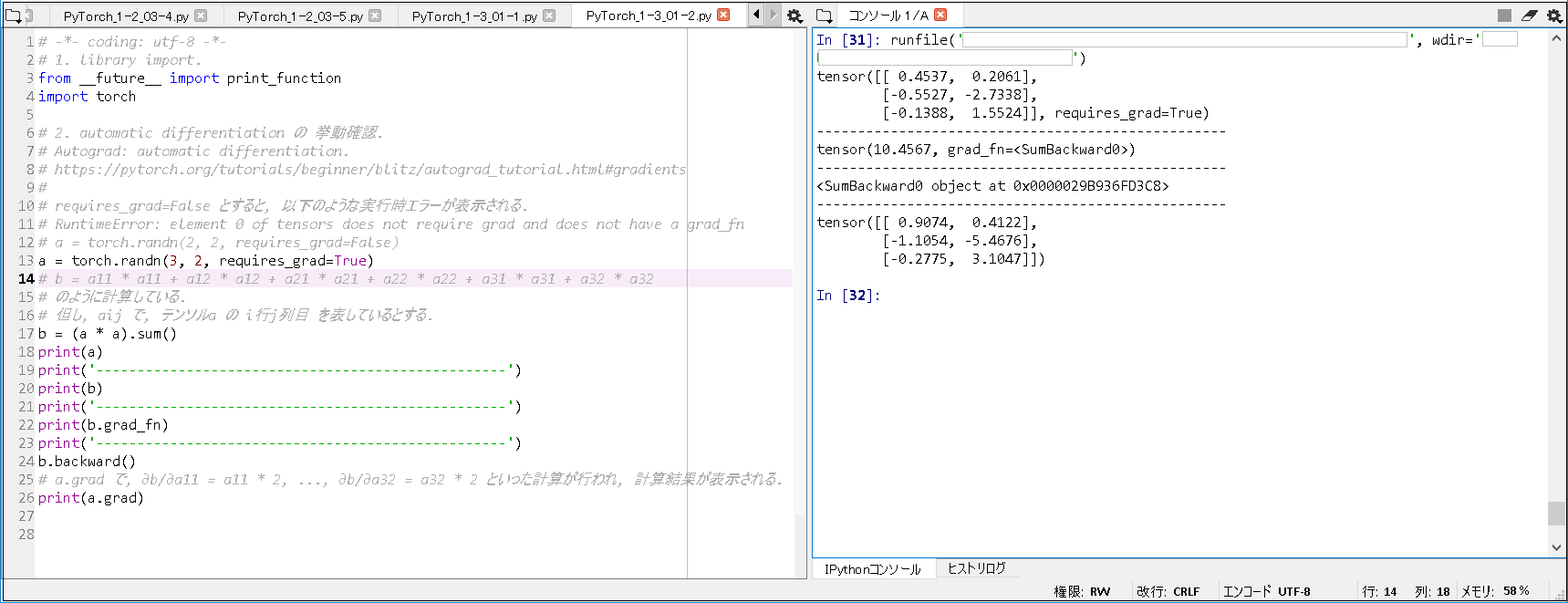
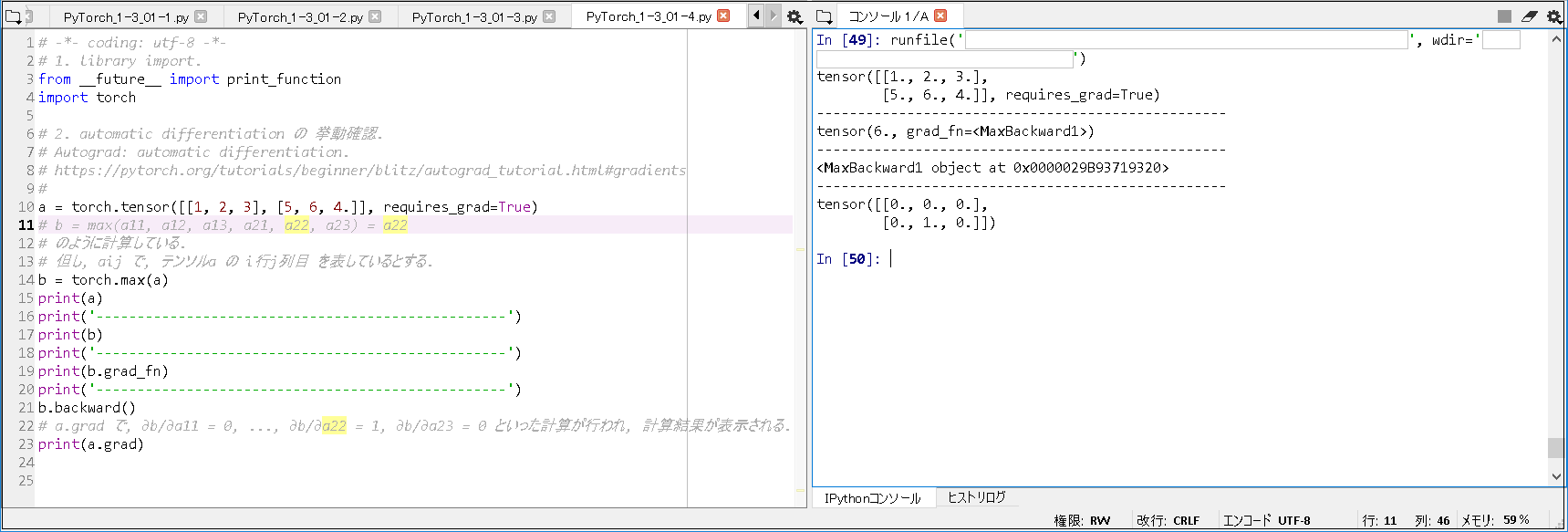
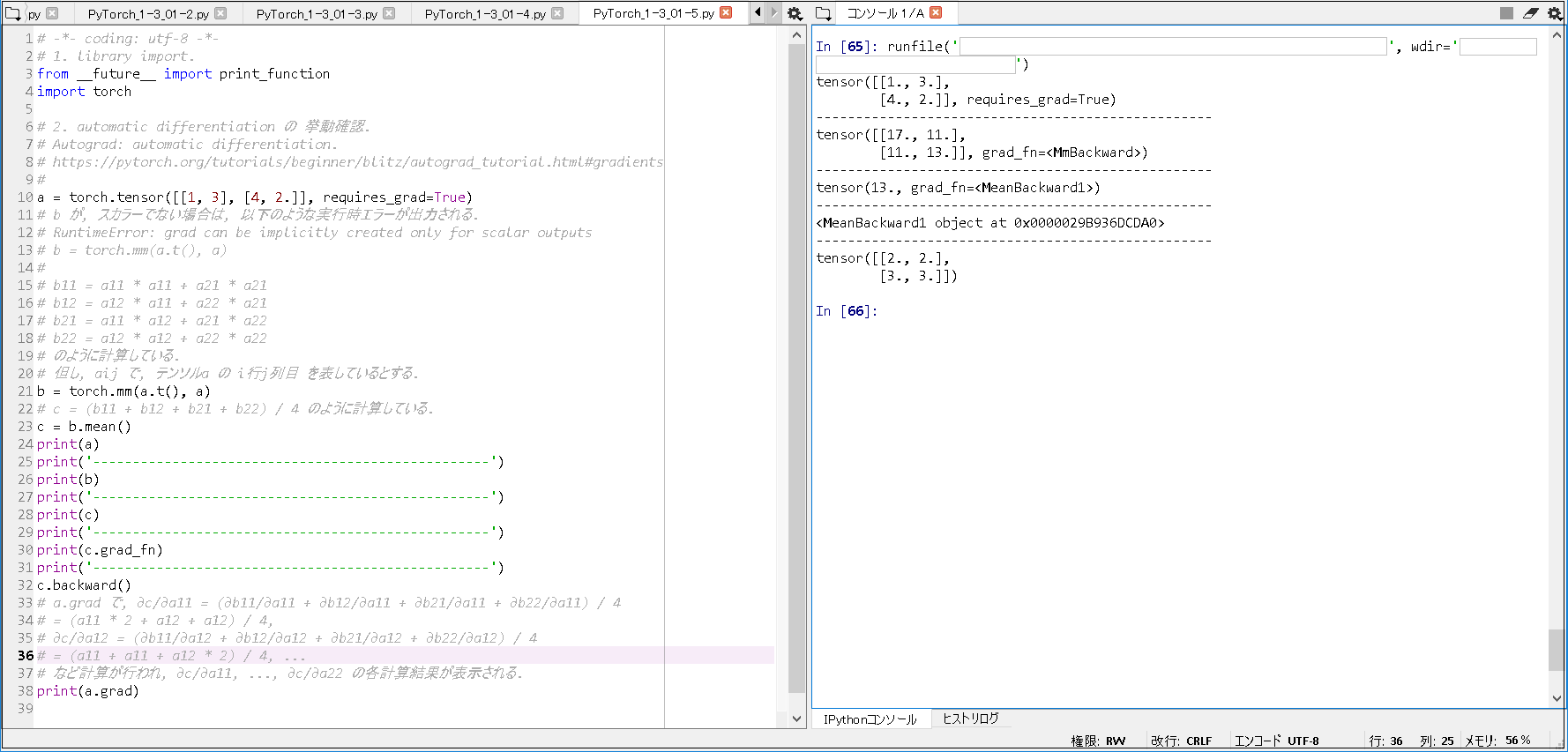
# tqdm を 下記コマンドで, install. # conda install -c conda-forge tqdm # 1. library import. from __future__ import print_function import torch from torchvision.datasets import FashionMNIST from torchvision import transforms from torch.utils.data import DataLoader import os, time from torch import nn, optim from tqdm import tqdm # 2. declare functions. # 2-1. A layer that stretches a Tensor of the (H, C, H, W) type to (N, C * H * W). # required to pass the output of convolution layer to MLP. class FlattenLayer(nn.Module): def forward(self, x): sizes = x.size() return x.view(sizes[0], - 1) ~(略)~ n, n_acc = 0, 0 for i ,(xx, yy) in tqdm(enumerate(train_loader), total=len(train_loader)): xx, yy = xx.to(device), yy.to(device) ~(略)~ # 5. execute training. net.to("cuda:0") train_net(net, train_loader, test_loader, n_iter=20, device="cuda:0") # 6. display processing time. end = time.time() print('--------------------------------------------------') print('Elapsed Time: ' + str(end - start) + "[sec]") |
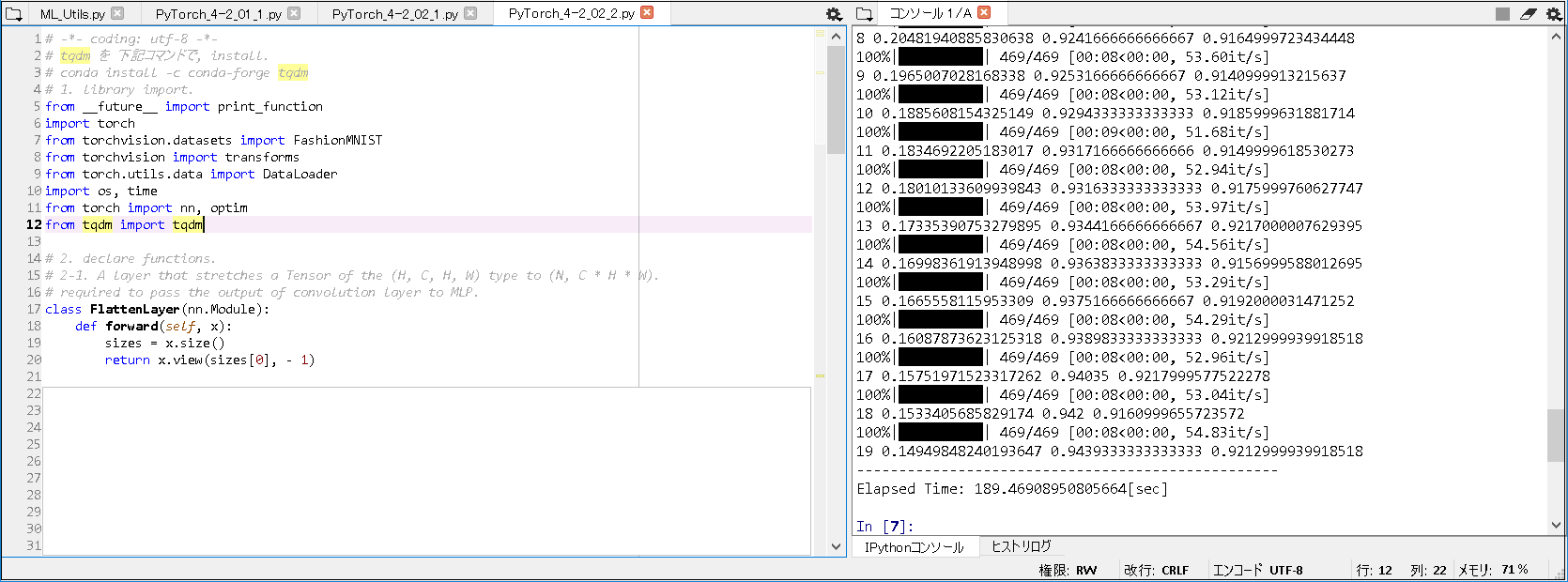
■実行結果(GPU版).
■Fashion-MNISTの学習(CPU版).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
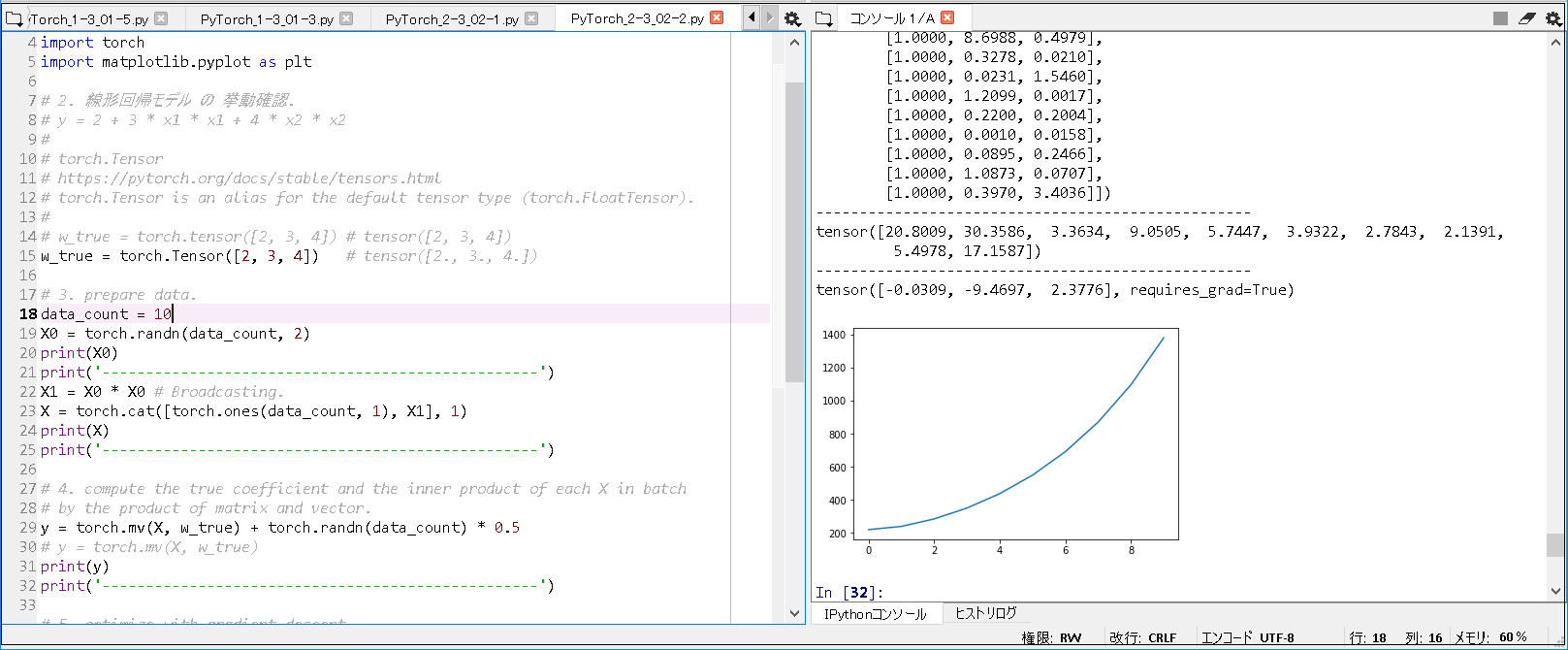
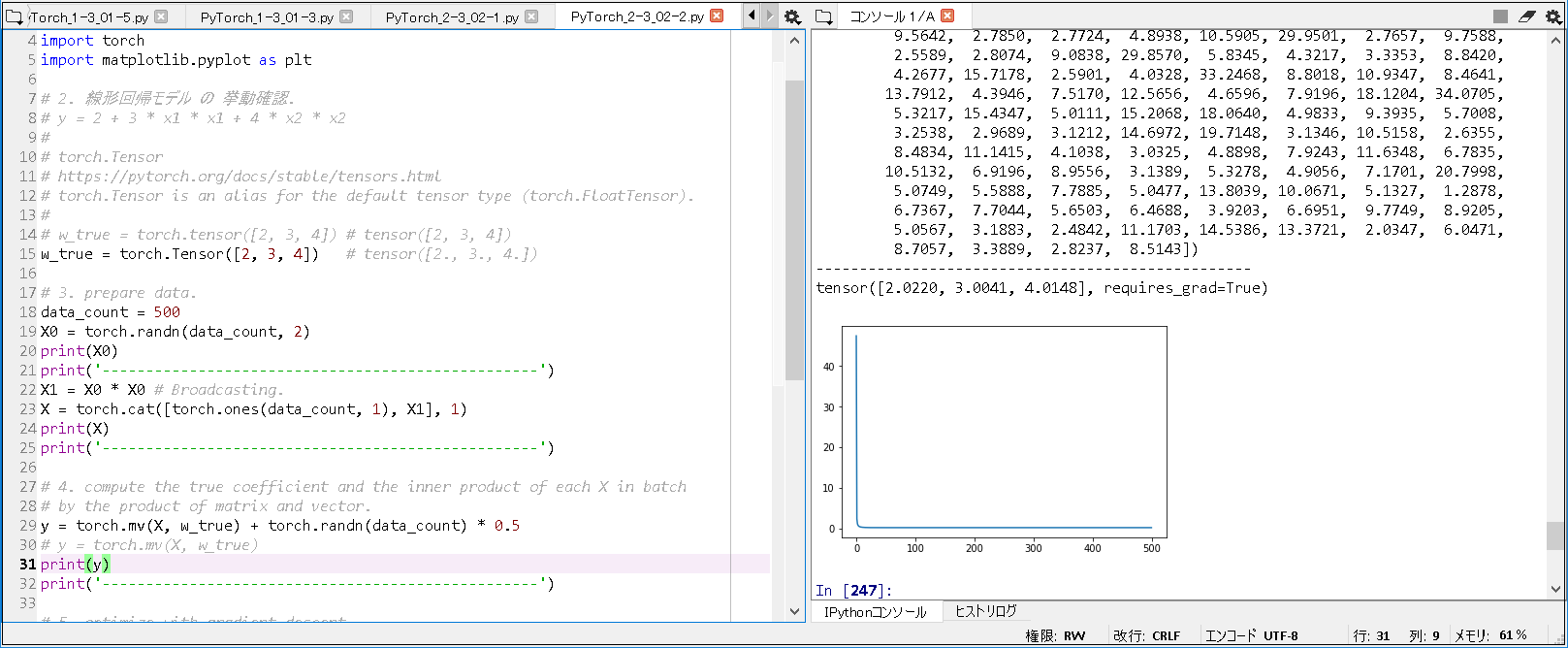
# -*- coding: utf-8 -*- # tqdm を 下記コマンドで, install. # conda install -c conda-forge tqdm # 1. library import. from __future__ import print_function import torch from torchvision.datasets import FashionMNIST from torchvision import transforms from torch.utils.data import DataLoader import os, time from torch import nn, optim from tqdm import tqdm # 2. declare functions. # 2-1. A layer that stretches a Tensor of the (H, C, H, W) type to (N, C * H * W). # required to pass the output of convolution layer to MLP. class FlattenLayer(nn.Module): def forward(self, x): sizes = x.size() return x.view(sizes[0], - 1) ~(略)~ n, n_acc = 0, 0 for i ,(xx, yy) in tqdm(enumerate(train_loader), total=len(train_loader)): xx, yy = xx.to(device), yy.to(device) ~(略)~ # 5. execute training. train_net(net, train_loader, test_loader, n_iter=20) # 6. display processing time. end = time.time() print('--------------------------------------------------') print('Elapsed Time: ' + str(end - start) + "[sec]") |
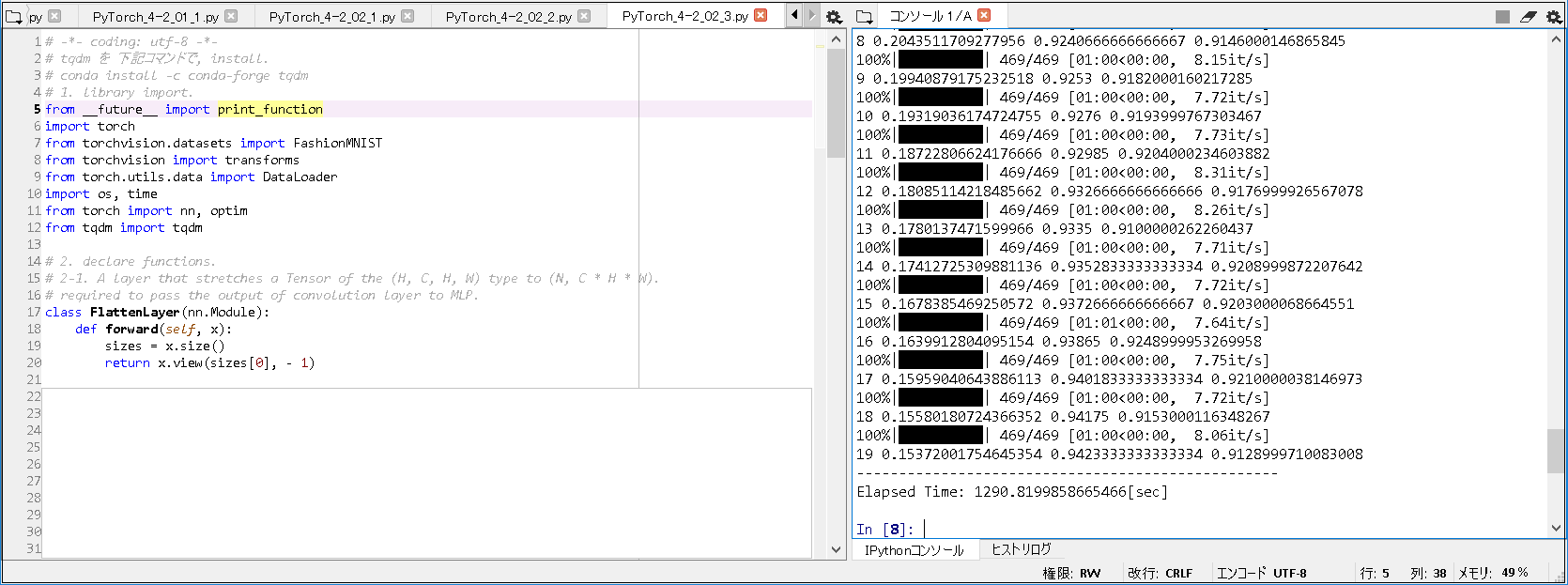
■実行結果(CPU版).
■以上の実行結果から, 以下のことが分かった.
① 処理速度.
実行結果(GPU版): Elapsed Time: 189.46908950805664[sec]
実行結果(CPU版): Elapsed Time: 1290.8199858665466[sec]
-> GPU版 が CPU版 に比べて, 約6.8倍早く処理できたことが分かった.
② tqdm の 使い方.
著書上の tqdm.tqdm(enumerate~(略)~ では, 動作しなかったので, tqdm(enumerate~(略)~ で 確認した.
■参考書籍
現場で使える! PyTorch開発入門 深層学習モデルの作成とアプリケーションへの実装 (AI & TECHNOLOGY)