
1. 環境は、Window 10 Home (64bit) 上で行った。
2. Anaconda3 (64bit) – Spyder上で、動作確認を行った。
3. python の バージョンは、python 3.7.0 である。
4. pytorch の バージョンは、pytorch 0.4.1 である。
5. GPU は, NVIDIA社 の GeForce GTX 1050 である。
6. CPU は, Intel社 の Core(TM) i7-7700HQ である。
今回確認した内容は、現場で使える! PyTorch開発入門 深層学習モデルの作成とアプリケーションへの実装 (AI & TECHNOLOGY) の 6.1 行列因子分解 (P.152 – P.159) である。
※1. プログラムの詳細は, 書籍を参考(P.152 – P.159)にして下さい.
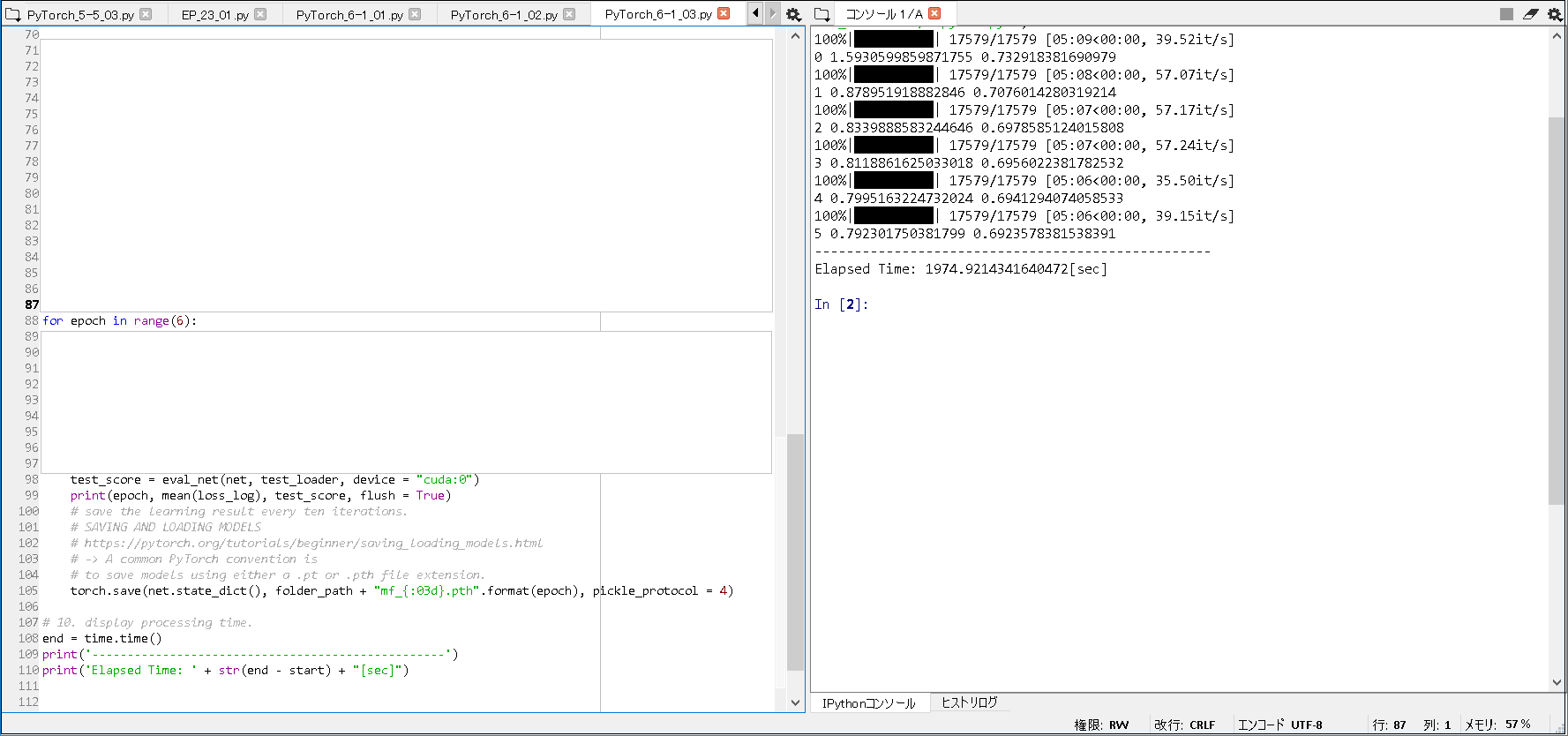
※2. 書籍上は, 本章に関し, 特に, 訓練したモデルの保存については, 書かれてなかったが, epoch 5 でも, 約1974秒かかったので, 訓練したモデルの保存は, 個人的には, 推奨したい.
■行列因子分解の訓練に関する動作確認.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
# -*- coding: utf-8 -*- # 1. library import. from __future__ import print_function import torch from torch import nn, optim from torch.utils.data import (DataLoader, TensorDataset) import os, time import pandas as pd from sklearn import model_selection from tqdm import tqdm from statistics import mean # 2. get csv data. # downloaded from the site below. # MovieLens # https://grouplens.org/datasets/movielens/ start = time.time() folder_path = os.path.expanduser('~') folder_path = folder_path + '\\.spyder-py3\\pytorch\\ml-20m\\' # X is a pair of userId, movieId. df = pd.read_csv(folder_path + 'ratings.csv', encoding = 'utf-8') ~(略)~ for epoch in range(6): ~(略)~ test_score = eval_net(net, test_loader, device = "cuda:0") print(epoch, mean(loss_log), test_score, flush = True) # save the learning result every ten iterations. # SAVING AND LOADING MODELS # https://pytorch.org/tutorials/beginner/saving_loading_models.html # -> A common PyTorch convention is # to save models using either a .pt or .pth file extension. torch.save(net.state_dict(), folder_path + "mf_{:03d}.pth".format(epoch), pickle_protocol = 4) # 10. display processing time. end = time.time() print('--------------------------------------------------') print('Elapsed Time: ' + str(end - start) + "[sec]") |
■実行結果(epoch 5).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
100%|██████████| 17579/17579 [05:09<00:00, 39.52it/s] 0 1.5930599859871755 0.732918381690979 100%|██████████| 17579/17579 [05:08<00:00, 57.07it/s] 1 0.878951918882846 0.7076014280319214 100%|██████████| 17579/17579 [05:07<00:00, 57.17it/s] 2 0.8339888583244646 0.6978585124015808 100%|██████████| 17579/17579 [05:07<00:00, 57.24it/s] 3 0.8118861625033018 0.6956022381782532 100%|██████████| 17579/17579 [05:06<00:00, 35.50it/s] 4 0.7995163224732024 0.6941294074058533 100%|██████████| 17579/17579 [05:06<00:00, 39.15it/s] 5 0.792301750381799 0.6923578381538391 -------------------------------------------------- Elapsed Time: 1974.9214341640472[sec] |
■指定ユーザの映画評価に関する予測についての動作確認.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 |
# -*- coding: utf-8 -*- # 1. library import. from __future__ import print_function import torch from torch import nn from torch.utils.data import (DataLoader, TensorDataset) import os, time import pandas as pd from sklearn import model_selection # 2. get csv data. # downloaded from the site below. # MovieLens # https://grouplens.org/datasets/movielens/ start = time.time() folder_path = os.path.expanduser('~') folder_path = folder_path + '\\.spyder-py3\\pytorch\\ml-20m\\' # X is a pair of userId, movieId. df = pd.read_csv(folder_path + 'ratings.csv', encoding = 'utf-8') ~(略)~ # 8. load model. net.load_state_dict(torch.load(folder_path + "mf_005.pth")) # 9. predict evaluation of user's movie. net.to("cpu") ~(略)~ # 10. calculate the evaluation prediction value of all movies for # a certain user and extract the top five. # query = torch.stack([ # torch.zeros(max_item).fill_(1), # torch.arange(1, max_item + 1)], 1).long() # -> RuntimeError: Expected a Tensor of type torch.FloatTensor # but found a type torch.LongTensor for sequence element 1 in sequence # argument at position #1 'tensors' # -> dtype = torch.float32 を 設定する形で, bug fix. query = torch.stack([ torch.zeros(max_item, dtype = torch.float32).fill_(1), torch.arange(1, max_item + 1, dtype = torch.float32)], 1).long() # torch.topk # https://pytorch.org/docs/stable/torch.html#torch.topk nq = net(query) scores, indices = torch.topk(nq, 5) print('- top five ---------------------------------------------') print('scores:', str(scores)) print('indices:', str(indices)) print() scores, indices = torch.topk(nq, 5, largest = False) print('- last five --------------------------------------------') print('scores:', str(scores)) print('indices:', str(indices)) print() scores, indices = torch.topk(nq, 100010) print('- between 25001 and 25010 ------------------------------') print('scores:', str(scores[25000 : 25010])) print('indices:', str(indices[25000 : 25010])) print() print('- between 50001 and 50010 ------------------------------') print('scores:', str(scores[50000 : 50010])) print('indices:', str(indices[50000 : 50010])) print() print('- between 75001 and 75010 ------------------------------') print('scores:', str(scores[75000 : 75010])) print('indices:', str(indices[75000 : 75010])) print() print('- between 100001 and 100010 ----------------------------') print('scores:', str(scores[100000 : 100010])) print('indices:', str(indices[100000 : 100010])) print() # 11. display processing time. end = time.time() print('--------------------------------------------------------') print('Elapsed Time: ' + str(end - start) + "[sec]") |
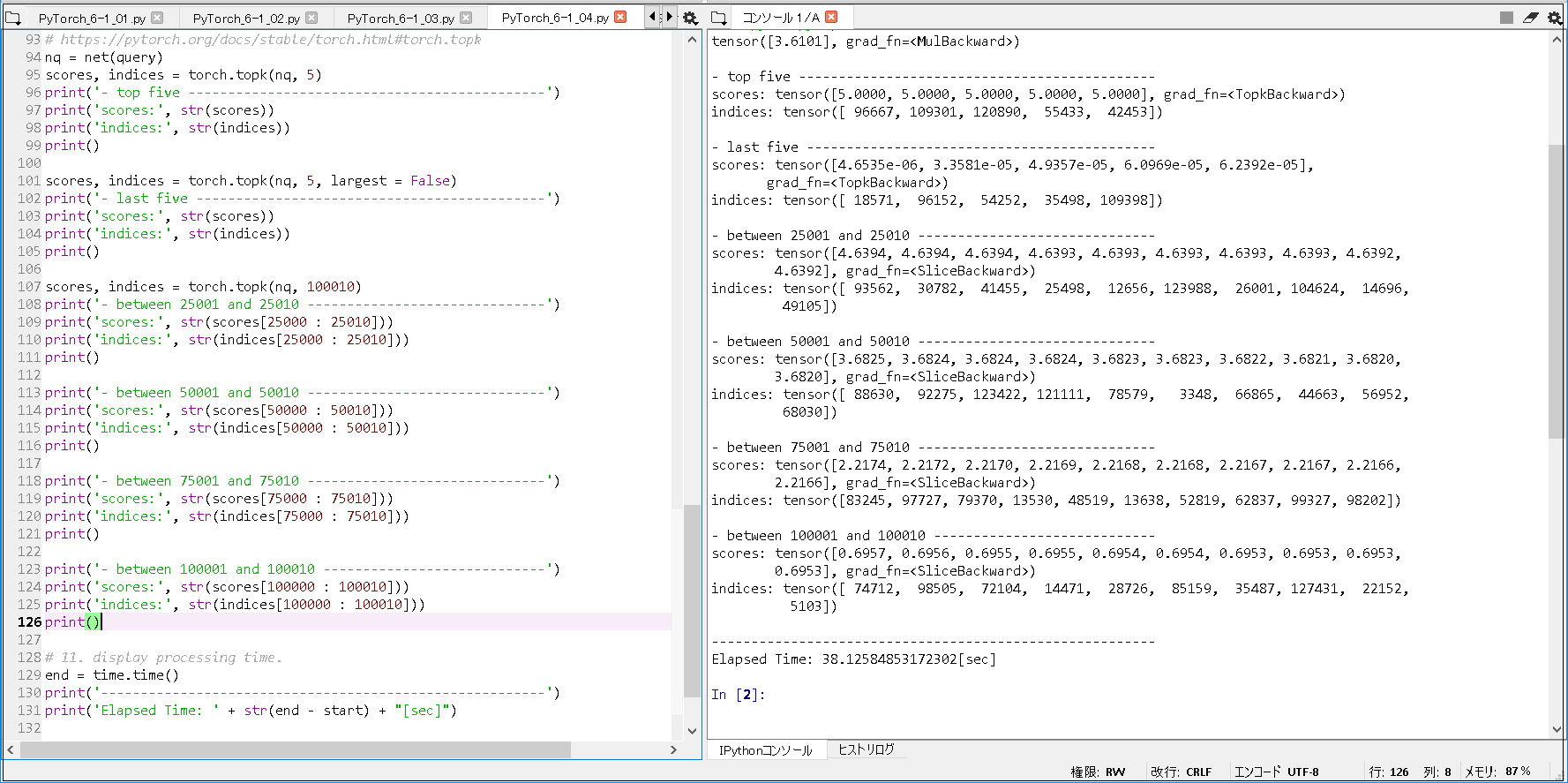
■実行結果.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
tensor([3.6101], grad_fn=<MulBackward>) - top five --------------------------------------------- scores: tensor([5.0000, 5.0000, 5.0000, 5.0000, 5.0000], grad_fn=<TopkBackward>) indices: tensor([ 96667, 109301, 120890, 55433, 42453]) - last five -------------------------------------------- scores: tensor([4.6535e-06, 3.3581e-05, 4.9357e-05, 6.0969e-05, 6.2392e-05], grad_fn=<TopkBackward>) indices: tensor([ 18571, 96152, 54252, 35498, 109398]) - between 25001 and 25010 ------------------------------ scores: tensor([4.6394, 4.6394, 4.6394, 4.6393, 4.6393, 4.6393, 4.6393, 4.6393, 4.6392, 4.6392], grad_fn=<SliceBackward>) indices: tensor([ 93562, 30782, 41455, 25498, 12656, 123988, 26001, 104624, 14696, 49105]) - between 50001 and 50010 ------------------------------ scores: tensor([3.6825, 3.6824, 3.6824, 3.6824, 3.6823, 3.6823, 3.6822, 3.6821, 3.6820, 3.6820], grad_fn=<SliceBackward>) indices: tensor([ 88630, 92275, 123422, 121111, 78579, 3348, 66865, 44663, 56952, 68030]) - between 75001 and 75010 ------------------------------ scores: tensor([2.2174, 2.2172, 2.2170, 2.2169, 2.2168, 2.2168, 2.2167, 2.2167, 2.2166, 2.2166], grad_fn=<SliceBackward>) indices: tensor([83245, 97727, 79370, 13530, 48519, 13638, 52819, 62837, 99327, 98202]) - between 100001 and 100010 ---------------------------- scores: tensor([0.6957, 0.6956, 0.6955, 0.6955, 0.6954, 0.6954, 0.6953, 0.6953, 0.6953, 0.6953], grad_fn=<SliceBackward>) indices: tensor([ 74712, 98505, 72104, 14471, 28726, 85159, 35487, 127431, 22152, 5103]) -------------------------------------------------------- Elapsed Time: 38.12584853172302[sec] |
■以上の実行結果から, 以下のことが分かった.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
1. MAEの確認. epoch 5 で, 約0.69 まで改善した(※書籍とほぼ同じ結果). 2. 行列因子分解の訓練. epoch 5 で, 約1974秒 かかった. 3. torch.stack()に関すること. RuntimeError: Expected a Tensor of type torch.FloatTensor but found a type torch.LongTensor for sequence element 1 in sequence argument at position #1 'tensors' -> 上記 error を回避するため, dtype = torch.float32 (2箇所) 指定する形で動作確認した. 4. 指定ユーザの映画評価の予測について. ・約38秒 かかった. ・Top5 だと, 評価5 ばかりだが, 例えば, 50001 ~ 50010位を見ると, 評価3.6 辺りに下降し, さらに, 100001 ~ 100010位では, 評価0.69 付近まで下降していることが確認できた. |
■参照サイト
【参照URL①】MovieLens
【参照URL②】SAVING AND LOADING MODELS
【参照URL③】torch.topk
■参考書籍
現場で使える! PyTorch開発入門 深層学習モデルの作成とアプリケーションへの実装 (AI & TECHNOLOGY)