
1. 環境は、Window 10 Home (64bit) 上で行った。
2. Anaconda3 (64bit) – Spyder上で、動作確認を行った。
3. python の バージョンは、python 3.7.0 である。
4. pytorch の バージョンは、pytorch 0.4.1 である。
5. GPU は, NVIDIA社 の GeForce GTX 1050 である。
6. CPU は, Intel社 の Core(TM) i7-7700HQ である。
今回確認した内容は、現場で使える! PyTorch開発入門 深層学習モデルの作成とアプリケーションへの実装 (AI & TECHNOLOGY) の 5.3 RNNと文章のクラス分類 (P.113 – P.121) である。
※1. プログラムの詳細は, 書籍を参考(P.113 – P.121)にして下さい.
※2. RNN の挙動について, 前回の課題として残していたものがあったので, 再度, 復習した.
※3. 参照URL① を 元に, positive, negative に関する予測, 正解に関する情報を出力させるなどの, 動作確認を行った.
-> DataLoaderの使い方で, 落とし穴があったので, 実行結果でも, コメントした.
■RNNと文章のクラス分類に関する動作確認(書籍から一部抜粋・加筆).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 |
# -*- coding: utf-8 -*- # 1. library import. from __future__ import print_function import torch from torch import nn, optim from torch.utils.data import (Dataset, DataLoader) from tqdm import tqdm from statistics import mean import os, re, pathlib, glob, time ~(略)~ # 3. create Dataset Class. class IMDBDataset(Dataset): def __init__(self, dir_path, train = True, max_len = 100, padding = True): ~(略)~ def __getitem__(self, idx): ~(略)~ subDirctory = os.path.basename(os.path.dirname(f)) print("idx: " + str(idx) + " " + str(subDirctory + "/" + str(os.path.basename(f)))) # print("n_tokens: " + str(n_tokens)) # ex. # idx: 0 neg/0_2.txt # idx: 1 neg/1_3.txt # idx: 2 pos/0_10.txt # idx: 3 pos/1_10.txt # -> idx から, ファイルを一意に識別できるはず. return data, label, n_tokens, idx # 4. create Dataset Class. start = time.time() folder_path = os.path.expanduser('~') # folder_path = folder_path + '\\.spyder-py3\\pytorch\\aclImdb\\' folder_path = folder_path + '\\.spyder-py3\\pytorch\\aclImdb_small\\' train_data = IMDBDataset(folder_path) test_data = IMDBDataset(folder_path, train = False) ~(略)~ # 6. create a training. # 6. create a training. def eval_net(net, data_loader, device="cpu"): net.eval() ys, ypreds, fs = [], [], [] for x, y, l, f in data_loader: # x=tensor([[ 10, 6, 3, 6269, 4804, ... # 4, 1, 16]],device='cuda:0') # y=tensor([0, 0, 1, 1], device='cuda:0') # l=tensor([100, 100, 100, 100], device='cuda:0') # f=tensor([2, 0, 1, 3], device='cuda:0') x, y, l, f = x.to(device), y.to(device), l.to(device), f.to(device) # print("x=" + repr(x)) # print("y=" + repr(y)) # print("l=" + repr(l)) # print("f=" + repr(f)) with torch.no_grad(): ~(略)~ fs.append(f) ~(略)~ fs = torch.cat(fs) acc = (ys == ypreds).float().sum() / len(ys) # print("ys size=" + str(ys.size()) + " ypreds size=" + str(ypreds.size()) + " fs size=" + str(fs.size())) # a = [1, 2, 3, 4, 5] # b = [1, 3, 4, 3, 5] # c = [i for i, j in zip(a, b) if i == j] # print(c) # [1, 5] # [index, k, i, j] は, loop の index, file の index, 正解ラベル, 予測ラベル の意味. # # zip-like function that pads to longest length? # https://stackoverflow.com/questions/1277278/zip-like-function-that-pads-to-longest-length # ys size=torch.Size([25000]) ypreds size=torch.Size([25000]) f size=torch.Size([8]) # -> file の index に関して, 取得方法が, bug となっていることが判明(torch.Size([25000])でないとおかしい). # -> リスト fs を用意して, f を保管するように, プログラムを修正して, bug fix とした. # ※ fs size=torch.Size([25000]) を確認できた. correct, wrong = [], [] for index, (k, i, j) in enumerate(zip(fs, ys, ypreds)): if i == j: correct.append([index, k, i, j]) else: wrong.append([index, k, i, j]) return acc.item(), correct, wrong, len(correct), len(wrong) ~(略)~ correct_list, wrong_list = [], [] for epoch in range(5): ~(略)~ for x, y, l, f in tqdm(train_loader): x, y, l, f = x.to("cuda:0"), y.to("cuda:0"), l.to("cuda:0"), f.to("cuda:0") ~(略)~ print('- train -----------------------------------------------') train_acc = eval_net(net, train_loader, "cuda:0") print('- test ------------------------------------------------') # idx: neg: 0 ~ 12499, pos: 12500 ~ 24999 val_acc = eval_net(net, test_loader, "cuda:0") print(epoch, mean(losses), train_acc[0], val_acc[0]) if epoch + 1 == 5: correct_list.append(val_acc[1]) wrong_list.append(val_acc[2]) print('--- display 3 wrong answers ------------------------------------------') # ex. # [[0, tensor(3, device='cuda:0'), tensor(1, device='cuda:0'), tensor(0, device='cuda:0')], # [2, tensor(1, device='cuda:0'), tensor(0, device='cuda:0'), tensor(1, device='cuda:0')]] # -> 上記のデータは, 以下のように理解できる. # 1. loop index = 0, file index = 3 に対応するテキストファイルは, pos/1_10.txt である. # 当該 RNNモデル で, negative(tensor(0, device='cuda:0')) と 予想したが, # 正解は, positive(tensor(1, device='cuda:0')) であるということ. # 2. loop index = 2, file index = 1 に対応するテキストファイルは, neg/1_3.txt である. # 当該 RNNモデル で, positive(tensor(1, device='cuda:0')) と 予想したが, # 正解は, negative(tensor(0, device='cuda:0')) であるということ. print(str(wrong_list[0][0:3])) print('--- display 3 correct answers ----------------------------------------') # ex. # [[1, tensor(0, device='cuda:0'), tensor(0, device='cuda:0'), tensor(0, device='cuda:0')], # [3, tensor(2, device='cuda:0'), tensor(1, device='cuda:0'), tensor(1, device='cuda:0')]] # -> 上記のデータは, 以下のように理解できる. # 1. loop index = 1, file index = 0 に対応するテキストファイルは, neg/0_2.txt である. # 当該 RNNモデル で, negative(tensor(0, device='cuda:0')) と 予想し, 正解と同じ結果だったということ. # 2. loop index = 3, file index = 2 に対応するテキストファイルは, pos/0_10.txt である. # 当該 RNNモデル で, positive(tensor(1, device='cuda:0')) と 予想し, 正解と同じ結果だったということ. print(str(correct_list[0][0:3])) # 6. display processing time. end = time.time() print('--------------------------------------------------') print('Elapsed Time: ' + str(end - start) + "[sec]") |
■実行結果.
1. [aclImdb_small]フォルダで確認(※データ数を少なくして検証)した場合(epoch = 5).
※以下のファイルで構成されているものとする.
imdb.vocab
aclImdb_small\train\neg\1_1.txt
aclImdb_small\train\neg\0_3.txt
aclImdb_small\train\pos\0_9.txt
aclImdb_small\train\pos\1_7.txt
aclImdb_small\train\unsup\0_0.txt
aclImdb_small\train\unsup\1_0.txt
aclImdb_small\test\neg\1_3.txt
aclImdb_small\test\neg\0_2.txt
aclImdb_small\test\pos\1_10.txt
aclImdb_small\test\pos\0_10.txt
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
0%| | 0/1 [00:00<?, ?it/s]idx: 3 pos/1_7.txt idx: 2 pos/0_9.txt idx: 0 neg/0_3.txt idx: 1 neg/1_1.txt 100%|██████████| 1/1 [00:00<00:00, 21.34it/s] - train ----------------------------------------------- idx: 2 pos/0_9.txt idx: 3 pos/1_7.txt idx: 1 neg/1_1.txt idx: 0 neg/0_3.txt - test ------------------------------------------------ idx: 0 neg/0_2.txt idx: 2 pos/0_10.txt idx: 3 pos/1_10.txt idx: 1 neg/1_3.txt 0 0.6945884227752686 0.5 0.5 ~(略)~ 0%| | 0/1 [00:00<?, ?it/s]idx: 3 pos/1_7.txt idx: 1 neg/1_1.txt idx: 0 neg/0_3.txt idx: 2 pos/0_9.txt 100%|██████████| 1/1 [00:00<00:00, 32.01it/s] - train ----------------------------------------------- idx: 3 pos/1_7.txt idx: 0 neg/0_3.txt idx: 1 neg/1_1.txt idx: 2 pos/0_9.txt - test ------------------------------------------------ idx: 3 pos/1_10.txt idx: 2 pos/0_10.txt idx: 0 neg/0_2.txt idx: 1 neg/1_3.txt 4 0.668656587600708 1.0 0.25 --- display 3 wrong answers ------------------------------------------ wrong answers: 3 count [[0, tensor(3, device='cuda:0'), tensor(1, device='cuda:0'), tensor(0, device='cuda:0')], [2, tensor(0, device='cuda:0'), tensor(0, device='cuda:0'), tensor(1, device='cuda:0')], [3, tensor(1, device='cuda:0'), tensor(0, device='cuda:0'), tensor(1, device='cuda:0')]] [tensor(3, device='cuda:0'), tensor(0, device='cuda:0'), tensor(1, device='cuda:0')] --- display 3 correct answers ---------------------------------------- correct answers: 1 count [[1, tensor(2, device='cuda:0'), tensor(1, device='cuda:0'), tensor(1, device='cuda:0')]] [tensor(2, device='cuda:0')] -------------------------------------------------- Elapsed Time: 0.8228132724761963[sec] |

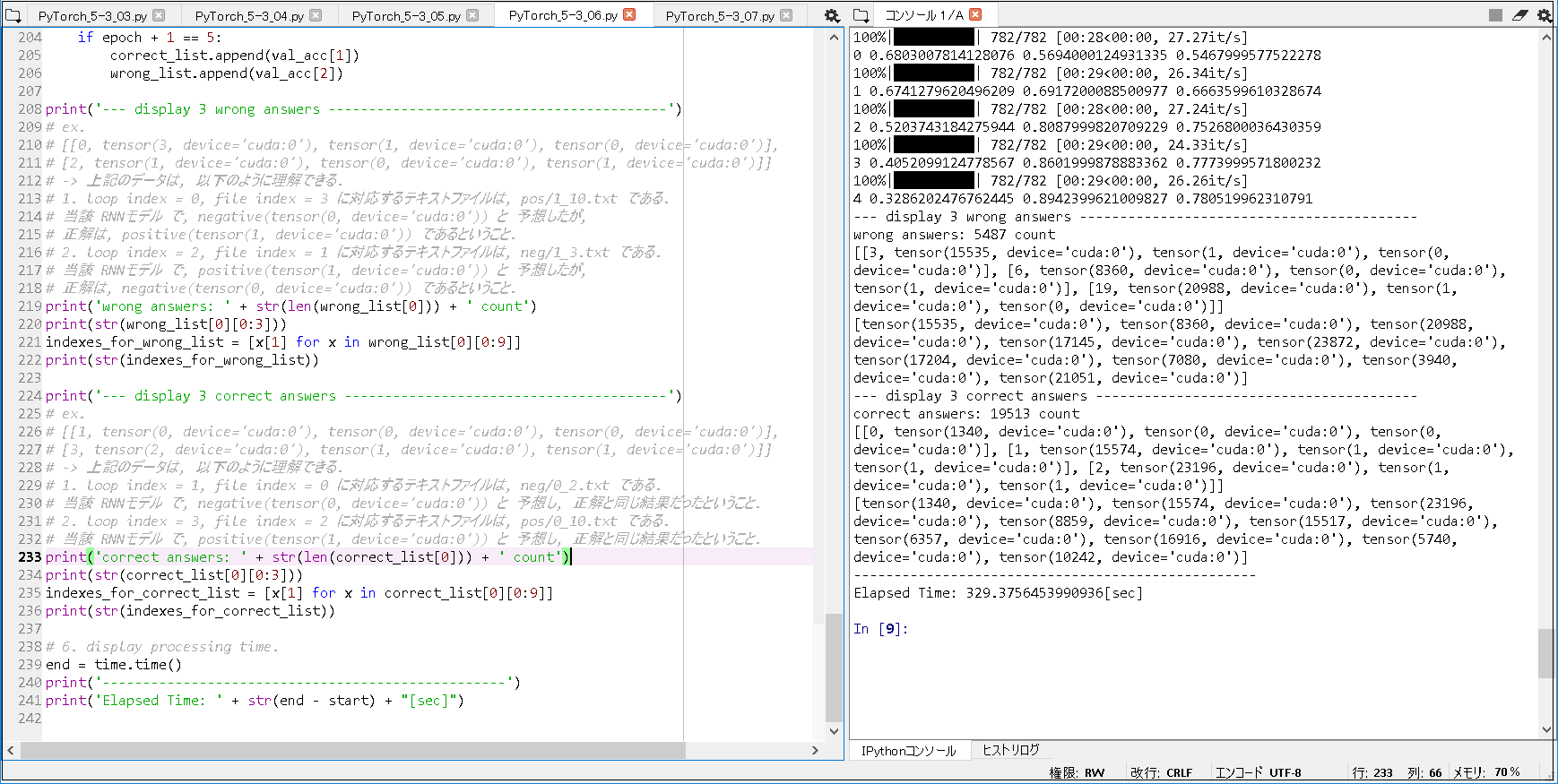
2. [aclImdb]フォルダで確認した場合(epoch = 5).
※[aclImdb/test/neg]フォルダ, [aclImdb/test/pos]フォルダ に, それぞれ, 12500枚ずつ の テキストファイルが保管されている.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
100%|██████████| 782/782 [00:28<00:00, 27.27it/s] 0 0.6803007814128076 0.5694000124931335 0.5467999577522278 100%|██████████| 782/782 [00:29<00:00, 26.34it/s] 1 0.6741279620496209 0.6917200088500977 0.6663599610328674 100%|██████████| 782/782 [00:28<00:00, 27.24it/s] 2 0.5203743184275944 0.8087999820709229 0.7526800036430359 100%|██████████| 782/782 [00:29<00:00, 24.33it/s] 3 0.4052099124778567 0.8601999878883362 0.7773999571800232 100%|██████████| 782/782 [00:29<00:00, 26.26it/s] 4 0.3286202476762445 0.8942399621009827 0.780519962310791 --- display 3 wrong answers ------------------------------------------ wrong answers: 5487 count [[3, tensor(15535, device='cuda:0'), tensor(1, device='cuda:0'), tensor(0, device='cuda:0')], [6, tensor(8360, device='cuda:0'), tensor(0, device='cuda:0'), tensor(1, device='cuda:0')], [19, tensor(20988, device='cuda:0'), tensor(1, device='cuda:0'), tensor(0, device='cuda:0')]] [tensor(15535, device='cuda:0'), tensor(8360, device='cuda:0'), tensor(20988, device='cuda:0'), tensor(17145, device='cuda:0'), tensor(23872, device='cuda:0'), tensor(17204, device='cuda:0'), tensor(7080, device='cuda:0'), tensor(3940, device='cuda:0'), tensor(21051, device='cuda:0')] --- display 3 correct answers ---------------------------------------- correct answers: 19513 count [[0, tensor(1340, device='cuda:0'), tensor(0, device='cuda:0'), tensor(0, device='cuda:0')], [1, tensor(15574, device='cuda:0'), tensor(1, device='cuda:0'), tensor(1, device='cuda:0')], [2, tensor(23196, device='cuda:0'), tensor(1, device='cuda:0'), tensor(1, device='cuda:0')]] [tensor(1340, device='cuda:0'), tensor(15574, device='cuda:0'), tensor(23196, device='cuda:0'), tensor(8859, device='cuda:0'), tensor(15517, device='cuda:0'), tensor(6357, device='cuda:0'), tensor(16916, device='cuda:0'), tensor(5740, device='cuda:0'), tensor(10242, device='cuda:0')] -------------------------------------------------- Elapsed Time: 329.3756453990936[sec] |
■実行結果.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
1. [aclImdb_small]フォルダで確認した場合. 精度: 25% テスト画像正解数: 4枚中, 1枚正解. 誤答に関する情報: ① loop index = 0, file index = 3 に対応するテキストファイルは, pos/1_10.txt である. 当該 RNNモデル で, negative(tensor(0, device='cuda:0')) と 予想したが, 正解は, positive(tensor(1, device='cuda:0')) であるということ. ② loop index = 2, file index = 0 に対応するテキストファイルは, neg/0_2.txt である. 当該 RNNモデル で, positive(tensor(1, device='cuda:0')) と 予想したが, 正解は, negative(tensor(0, device='cuda:0')) であるということ. ③ loop index = 3, file index = 1 に対応するテキストファイルは, neg/1_3.txt である. 当該 RNNモデル で, positive(tensor(1, device='cuda:0')) と 予想したが, 正解は, negative(tensor(0, device='cuda:0')) であるということ. 2. [aclImdb]フォルダで確認した場合. 精度: 約78% テスト画像正解数: 25000枚中, 19513枚正解. 誤答に関する情報: ① loop index = 3, file index = 15535 に対応するテキストファイルは, pos/1482_10.txt である. 当該 RNNモデル で, negative(tensor(0, device='cuda:0')) と 予想したが, 正解は, positive(tensor(1, device='cuda:0')) であるということ. ② loop index = 6, file index = 8360 に対応するテキストファイルは, neg/6275_1.txt である. 当該 RNNモデル で, positive(tensor(1, device='cuda:0')) と 予想したが, 正解は, negative(tensor(0, device='cuda:0')) であるということ. ③ loop index = 19, file index = 20988 に対応するテキストファイルは, pos/6390_10.txt である. 当該 RNNモデル で, negative(tensor(0, device='cuda:0')) と 予想したが, 正解は, positive(tensor(1, device='cuda:0')) であるということ. ※上記, 誤答に関する情報で, 対応するテキストファイルの特定については, IMDBDatasetクラス の __getitem__関数内で, 別途, 以下の内容で確認した. subDirctory = os.path.basename(os.path.dirname(f)) if idx == 15535 or idx == 8360 or idx == 20988: print("idx: " + str(idx) + " " + str(subDirctory + "/" + str(os.path.basename(f)))) 3. eval_net関数での file の index 取得について. data_loader から取り出した f を そのまま使うと, サイズ(torch.Size([8]))を確認すると分かるように, 誤った出力結果となる. -> リスト fs を用意して, f を保管するように, 対応する必要があることに注意. -> リストfs を テンソルに変換後は, 想定していたサイズ(torch.Size([25000]))となっていることが確認できた. 4. 誤答した文章の例(test/pos/6390_10.txt). It gives the ordinary guy/girl the chance to be on television singing as their favourite stars.<br /><br />For the majority of the time, they sound like the singer they are meant to be portraying.<br /><br />Another twist to it - A team of make up people and costumers dress the contestant up like that singer. They might not look like them but the likelihood of getting someone that sounds like a person looking exactly the same as them are very slim.<br /><br />It's a load of fun for your Saturday night - and the contestants aren't raging wannabes like they are on another TV singing show. The fact that there are no prizes involved and it is for fun means that it will attract a different type of person.<br /><br />The only gripe i have is with the Kids version - it looks like they have done the round of stage schools- what happened to the normal kids? -> 上記文章について, RNNモデルでは, negativeと予想し, positiveが正解のため, 誤答となったが, 個人的に, Google 翻訳などで上記文章を読んでみても, positive なのか, negative なのか, 判別できなかった(positive とも negative とも, 受け取れるように見える...汗). |
■参照サイト
【参照URL①】DataLoader Filenames in each Batch
【参照URL②】zip-like function that pads to longest length?
■参考書籍
現場で使える! PyTorch開発入門 深層学習モデルの作成とアプリケーションへの実装 (AI & TECHNOLOGY)