
1. 環境は、Window 10 Home (64bit) 上で行った。
2. Anaconda3 (64bit) – Spyder上で、動作確認を行った。
3. python の バージョンは、python 3.7.0 である。
4. pytorch の バージョンは、pytorch 0.4.1 である。
5. GPU は, NVIDIA社 の GeForce GTX 1050 である。
6. CPU は, Intel社 の Core(TM) i7-7700HQ である。
今回確認した内容は、現場で使える! PyTorch開発入門 深層学習モデルの作成とアプリケーションへの実装 (AI & TECHNOLOGY) の 5.3 RNNと文章のクラス分類 (P.113 – P.121) である。
※1. プログラムの詳細は, 書籍を参考(P.113 – P.121)にして下さい.
※2. とりあえず出力されるところまで, 動作確認を行った.
■RNNと文章のクラス分類に関する動作確認(書籍から一部抜粋・加筆).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
# -*- coding: utf-8 -*- # 1. library import. from __future__ import print_function import torch from torch import nn, optim from torch.utils.data import (Dataset, DataLoader) from tqdm import tqdm from statistics import mean import os, re, pathlib, glob, time ~(略)~ # 3. create Dataset Class. class IMDBDataset(Dataset): def __init__(self, dir_path, train = True, max_len = 100, padding = True): ~(略)~ # read vocabulary files and divide them line by line. # UnicodeDecodeError: 'cp932' codec can't decode byte 0x9f in position 290036: # illegal multibyte sequence # -> 上記のようなerrorが出力されたので, encoding="utf-8" を指定. # WindowsでCP932(Shift-JIS)エンコード以外のファイルを開くのに苦労した話 # https://qiita.com/Yuu94/items/9ffdfcb2c26d6b33792e # self.vocab_array = vocab_path.open().read().strip().splitlines() self.vocab_array = vocab_path.open(encoding="utf-8").read().strip().splitlines() ~(略)~ def __getitem__(self, idx): label, f = self.labeled_files[idx] # read text data of file and convert it to lower case. # UnicodeDecodeError: 'cp932' codec can't decode byte 0x96 in position 80: # illegal multibyte sequence # -> 上記のようなerrorが出力されたので, encoding="utf-8" を指定. # WindowsでCP932(Shift-JIS)エンコード以外のファイルを開くのに苦労した話 # https://qiita.com/Yuu94/items/9ffdfcb2c26d6b33792e # data = open(f).read().lower() data = open(f, encoding="utf-8").read().lower() ~(略)~ # 4. create Dataset Class. start = time.time() folder_path = os.path.expanduser('~') folder_path = folder_path + '\\.spyder-py3\\pytorch\\aclImdb\\' train_data = IMDBDataset(folder_path) test_data = IMDBDataset(folder_path, train = False) # BrokenPipeError: [Errno 32] Broken pipe # -> 上記のようなerrorが出力されたので, num_workers = 0 を指定. # BrokenPipeError: [Errno 32] Broken pipe #4418 # https://github.com/pytorch/pytorch/issues/4418 # train_loader = DataLoader(train_data, batch_size = 32, shuffle = True, num_workers = 4) # test_loader = DataLoader(test_data, batch_size = 32, shuffle = True, num_workers = 4) train_loader = DataLoader(train_data, batch_size = 32, shuffle = True, num_workers = 0) test_loader = DataLoader(test_data, batch_size = 32, shuffle = True, num_workers = 0) ~(略)~ # 6. display processing time. end = time.time() print('--------------------------------------------------') print('Elapsed Time: ' + str(end - start) + "[sec]") |
■実行結果.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
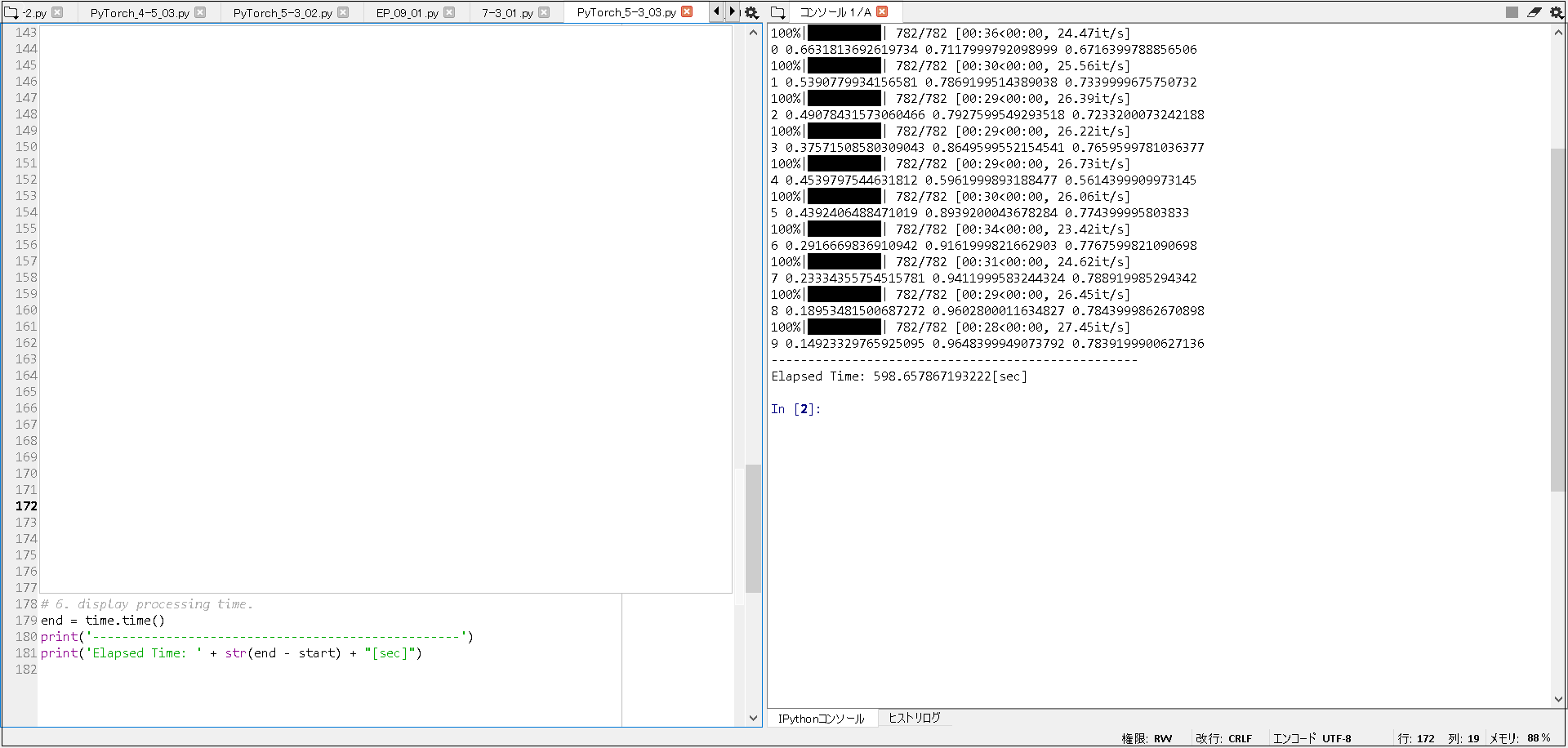
100%|██████████| 782/782 [00:36<00:00, 24.47it/s] 0 0.6631813692619734 0.7117999792098999 0.6716399788856506 100%|██████████| 782/782 [00:30<00:00, 25.56it/s] 1 0.5390779934156581 0.7869199514389038 0.7339999675750732 100%|██████████| 782/782 [00:29<00:00, 26.39it/s] 2 0.49078431573060466 0.7927599549293518 0.7233200073242188 100%|██████████| 782/782 [00:29<00:00, 26.22it/s] 3 0.37571508580309043 0.8649599552154541 0.7659599781036377 100%|██████████| 782/782 [00:29<00:00, 26.73it/s] 4 0.4539797544631812 0.5961999893188477 0.5614399909973145 100%|██████████| 782/782 [00:30<00:00, 26.06it/s] 5 0.4392406488471019 0.8939200043678284 0.774399995803833 100%|██████████| 782/782 [00:34<00:00, 23.42it/s] 6 0.2916669836910942 0.9161999821662903 0.7767599821090698 100%|██████████| 782/782 [00:31<00:00, 24.62it/s] 7 0.23334355754515781 0.9411999583244324 0.788919985294342 100%|██████████| 782/782 [00:29<00:00, 26.45it/s] 8 0.18953481500687272 0.9602800011634827 0.7843999862670898 100%|██████████| 782/782 [00:28<00:00, 27.45it/s] 9 0.14923329765925095 0.9648399949073792 0.7839199900627136 -------------------------------------------------- Elapsed Time: 598.657867193222[sec] |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
1. ファイルオープン時のエラー. UnicodeDecodeError: 'cp932' codec can't decode byte... -> 本件は, 参照URL① を元に, encoding="utf-8" を設定することで回避できた. 2. DataLoaderの設定値に関するエラー. BrokenPipeError: [Errno 32] Broken pipe -> 本件は, 参照URL② を元に, num_workers = 0 を設定することで回避できた. 3. 実行時間について, 以下の結果だった. Elapsed Time: 598.657867193222[sec] 4.精度について, 以下の結果だった. 約78% -> 書籍では, 約77% であるため, ほぼ一致していた. |
■参照サイト
【参照URL①】WindowsでCP932(Shift-JIS)エンコード以外のファイルを開くのに苦労した話
【参照URL②】BrokenPipeError: [Errno 32] Broken pipe #4418
■参考書籍
現場で使える! PyTorch開発入門 深層学習モデルの作成とアプリケーションへの実装 (AI & TECHNOLOGY)