
1. 環境は、Window 10 Home (64bit) 上で行った。
2. Anaconda3 (64bit) – Spyder上で、動作確認を行った。
3. python の バージョンは、python 3.7.0 である。
4. pytorch の バージョンは、pytorch 0.4.1 である。
5. GPU は, NVIDIA社 の GeForce GTX 1050 である。
6. CPU は, Intel社 の Core(TM) i7-7700HQ である。
今回確認した内容は、現場で使える! PyTorch開発入門 深層学習モデルの作成とアプリケーションへの実装 (AI & TECHNOLOGY) の 5.1 RNNとは ~ (P.108 – P.114) である。
※1. プログラムの詳細は, 書籍を参考(P.108 – P.114)にして下さい.
※2. 今回は, PyTorch というよりは, 寧ろ Pythonの正規表現 の確認となったように思う.
※3. 併せて, 書籍上の関数(text2ids, list2tensor)について, 簡単な動作確認を行った.
■text2ids, list2tensorの動作確認(書籍の関数).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
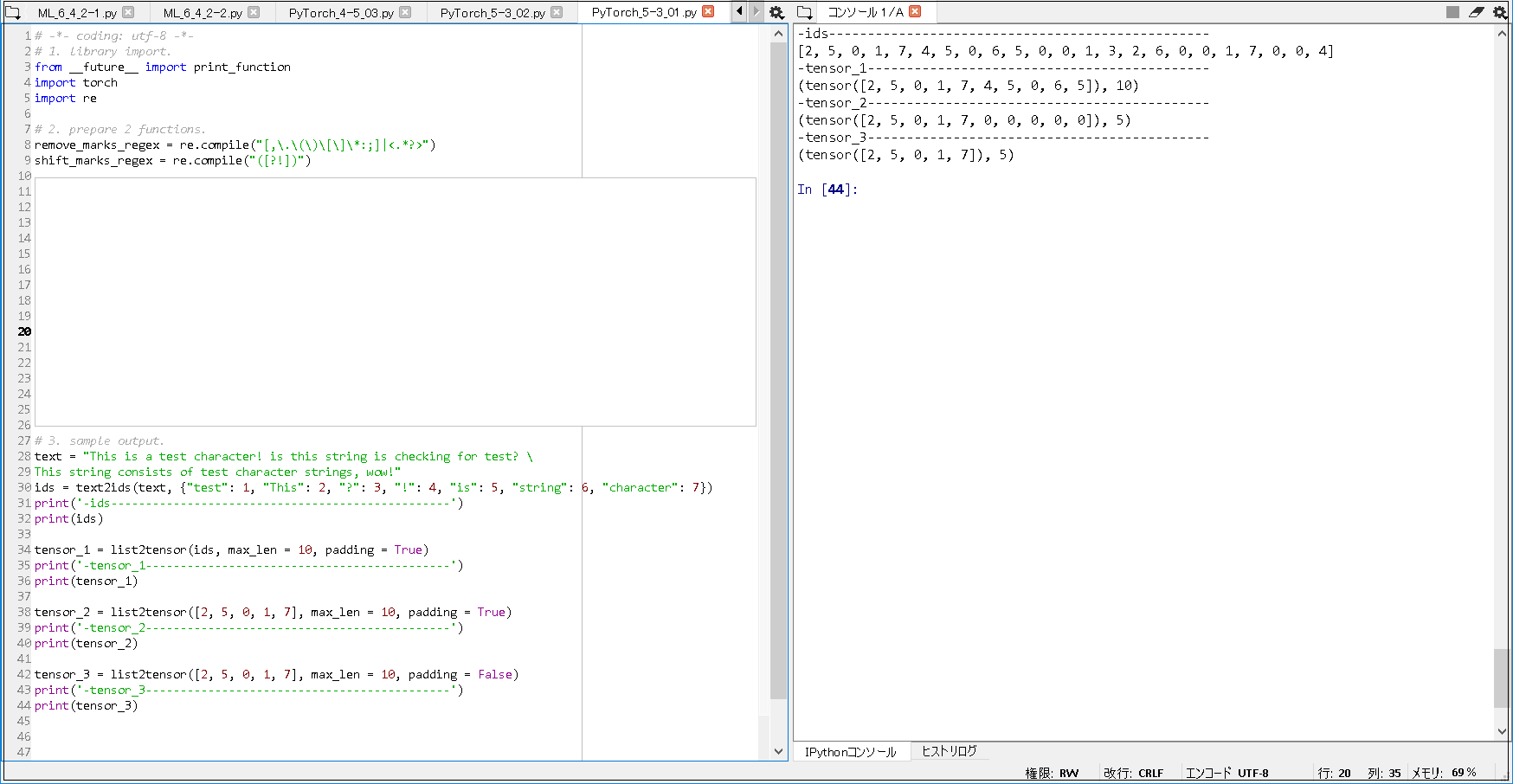
# -*- coding: utf-8 -*- # 1. library import. from __future__ import print_function import torch import re ~(略)~ # 3. sample output. text = "This is a test character! is this string is checking for test? \ This string consists of test character strings, wow!" ids = text2ids(text, {"test": 1, "This": 2, "?": 3, "!": 4, "is": 5, "string": 6, "character": 7}) print('-ids-------------------------------------------------') print(ids) tensor_1 = list2tensor(ids, max_len = 10, padding = True) print('-tensor_1--------------------------------------------') print(tensor_1) tensor_2 = list2tensor([2, 5, 0, 1, 7], max_len = 10, padding = True) print('-tensor_2--------------------------------------------') print(tensor_2) tensor_3 = list2tensor([2, 5, 0, 1, 7], max_len = 10, padding = False) print('-tensor_3--------------------------------------------') print(tensor_3) |
■実行結果.
|
1 2 3 4 5 6 7 8 |
-ids------------------------------------------------- [2, 5, 0, 1, 7, 4, 5, 0, 6, 5, 0, 0, 1, 3, 2, 6, 0, 0, 1, 7, 0, 0, 4] -tensor_1-------------------------------------------- (tensor([2, 5, 0, 1, 7, 4, 5, 0, 6, 5]), 10) -tensor_2-------------------------------------------- (tensor([2, 5, 0, 1, 7, 0, 0, 0, 0, 0]), 5) -tensor_3-------------------------------------------- (tensor([2, 5, 0, 1, 7]), 5) |
■正規表現の動作確認(書籍から一部抜粋・加筆).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
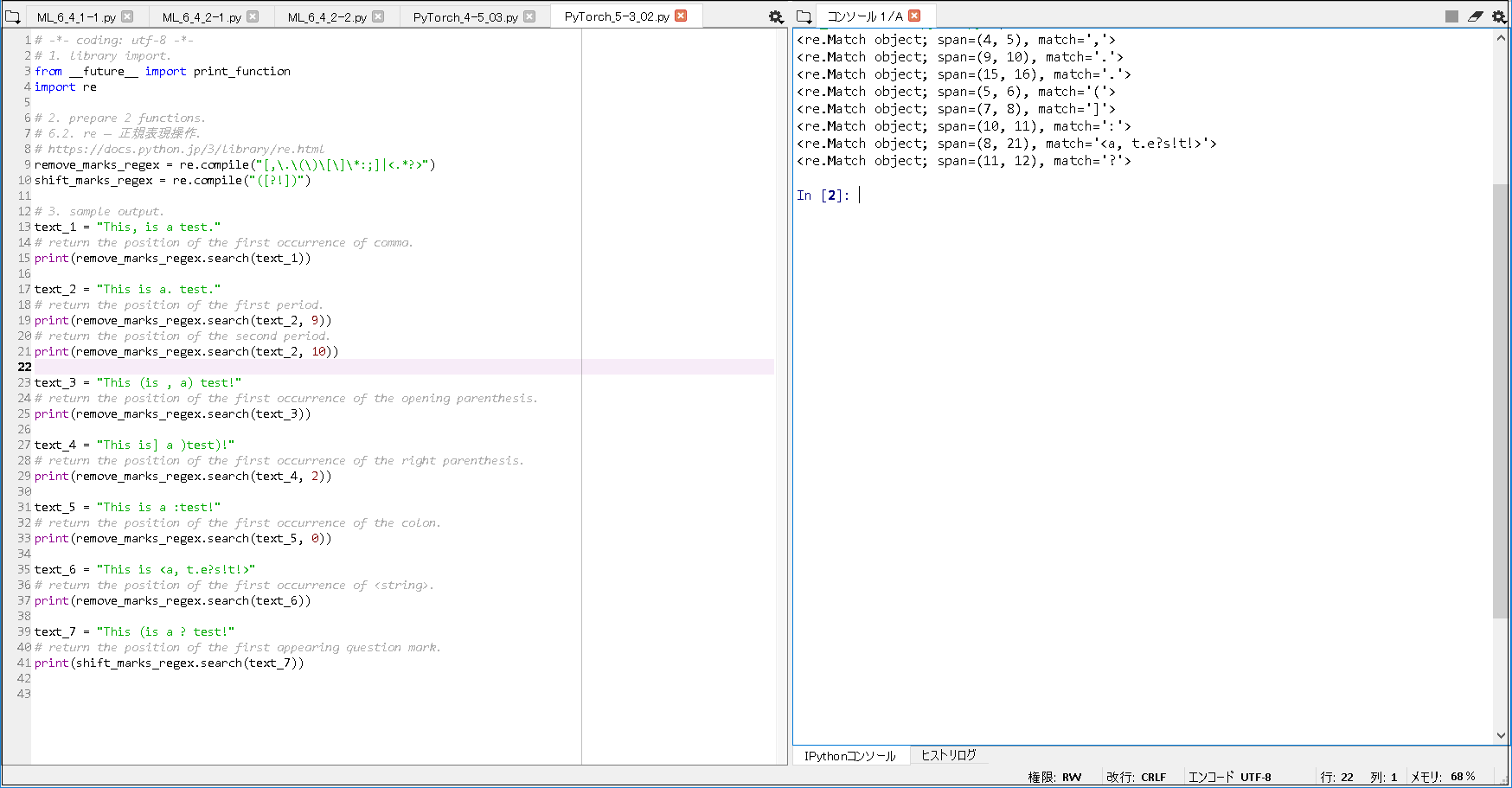
# -*- coding: utf-8 -*- # 1. library import. from __future__ import print_function import re # 2. prepare 2 functions. # 6.2. re — 正規表現操作. # https://docs.python.jp/3/library/re.html remove_marks_regex = re.compile("[,\.\(\)\[\]\*:;]|<.*?>") shift_marks_regex = re.compile("([?!])") # 3. sample output. text_1 = "This, is a test." # return the position of the first occurrence of comma. print(remove_marks_regex.search(text_1)) text_2 = "This is a. test." # return the position of the first period. print(remove_marks_regex.search(text_2, 9)) # return the position of the second period. print(remove_marks_regex.search(text_2, 10)) text_3 = "This (is , a) test!" # return the position of the first occurrence of the opening parenthesis. print(remove_marks_regex.search(text_3)) text_4 = "This is] a )test)!" # return the position of the first occurrence of the right parenthesis. print(remove_marks_regex.search(text_4, 2)) text_5 = "This is a :test!" # return the position of the first occurrence of the colon. print(remove_marks_regex.search(text_5, 0)) text_6 = "This is <a, t.e?s!t!>" # return the position of the first occurrence of <string>. print(remove_marks_regex.search(text_6)) text_7 = "This (is a ? test!" # return the position of the first appearing question mark. print(shift_marks_regex.search(text_7)) |
■実行結果.
|
1 2 3 4 5 6 7 8 |
<re.Match object; span=(4, 5), match=','> <re.Match object; span=(9, 10), match='.'> <re.Match object; span=(15, 16), match='.'> <re.Match object; span=(5, 6), match='('> <re.Match object; span=(7, 8), match=']'> <re.Match object; span=(10, 11), match=':'> <re.Match object; span=(8, 21), match='<a, t.e?s!t!>'> <re.Match object; span=(11, 12), match='?'> |
■参照サイト
【参照URL①】6.2. re — 正規表現操作
■参考書籍
現場で使える! PyTorch開発入門 深層学習モデルの作成とアプリケーションへの実装 (AI & TECHNOLOGY)