
1. 環境は、Window 10 Home (64bit) 上で行った。
2. Anaconda3 (64bit) – Spyder上で、動作確認を行った。
3. python の バージョンは、python 3.7.0 である。
4. pytorch の バージョンは、pytorch 0.4.1 である。
5. GPU は, NVIDIA社 の GeForce GTX 1050 である。
6. CPU は, Intel社 の Core(TM) i7-7700HQ である。
今回確認した内容は、現場で使える! PyTorch開発入門 深層学習モデルの作成とアプリケーションへの実装 (AI & TECHNOLOGY) の 4.3.1 転移学習(P.072 – P.082) である。
※1. プログラムの詳細は、書籍を参考(P.072 – P.082)にして下さい。
※2. 転移学習の挙動について, もう少し深めたかったので, 再度, 復習した.
※3. 画像を出力させるなどして, 再度動作確認してみた.
■転移学習(自作CNNモデル).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 |
# -*- coding: utf-8 -*- # 1. library import. from __future__ import print_function import torch import torchvision from torch import nn, optim from torch.utils.data import DataLoader from torchvision.datasets import ImageFolder from torchvision import transforms from tqdm import tqdm import numpy as np import matplotlib.pyplot as plt import time # 2. display image function. # TRANSFER LEARNING TUTORIAL # https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html def imshow(inp, title=None): """Imshow for Tensor.""" inp = inp.numpy().transpose((1, 2, 0)) # mean = np.array([0.485, 0.456, 0.406]) # std = np.array([0.229, 0.224, 0.225]) # inp = std * inp + mean # inp = np.clip(inp, 0, 1) plt.axis('off') plt.imshow(inp) if title is not None: plt.title(title) # plt.pause(0.001) # pause a bit so that plots are updated # 3. describe the model training function. def eval_net(net, data_loader, device="cpu"): ~(略)~ # calculate prediction accuracy. acc = (ys == ypreds).float().sum() / len(ys) # a = [1, 2, 3, 4, 5] # b = [1, 3, 4, 3, 5] # c = [i for i, j in zip(a, b) if i == j] # print(c) # [1, 5] # [index, i, j] は, 画像のindex, 正解ラベル, 予測ラベル の意味. correct, wrong = [], [] for index, (i, j) in enumerate(zip(ys, ypreds)): if i == j: correct.append([index, i, j]) else: wrong.append([index, i, j]) return acc.item(), correct, wrong, len(correct), len(wrong) def train_net(net, train_loader, test_loader, only_fc= True, optimizer_cls = optim.Adam, loss_fn = nn.CrossEntropyLoss(), n_iter = 10, device = "cpu"): ~(略)~ correct_list, wrong_list = [], [] for epoch in range(n_iter): ~(略)~ e = eval_net(net, test_loader, device) val_acc.append(e[0]) if epoch + 1 == n_iter: correct_list.append(e[1]) wrong_list.append(e[2]) print(epoch, train_losses[-1], train_acc[-1], val_acc[-1], flush=True) return correct_list, wrong_list, e[3], e[4] ~(略)~ # 5. Create DataLoader with a batch size of 128 respectively. train_loader = DataLoader(train_imgs, batch_size=64, shuffle=True) test_loader = DataLoader(test_imgs, batch_size=64, shuffle=False) # https://github.com/andreh7/ecal-rechits-pytorch-training/blob/master/FlattenLayer.py class FlattenLayer(nn.Module): # a 'View' reshaping the input to dimension (minibatch, product of remaining dimensions) # typically to be used after a convolutional network and before the dense layers ### def __init__(self): ### super(FlattenLayer, self).__init__() def forward(self, x): # see e.g. https://github.com/pytorch/vision/blob/master/torchvision/models/alexnet.py#L44 # https://pytorch.org/docs/stable/tensors.html # the size -1 is inferred from other dimensions # print(x.size()) # torch.Size([1, 192, 3, 3]) return x.view(x.size(0), -1) def __repr__(self): return self.__class__.__name__ + " ()" # 定番のConvolutional Neural Networkをゼロから理解する. # https://deepage.net/deep_learning/2016/11/07/convolutional_neural_network.html # in: torch.Size([1, 3, 224, 224]) # out: torch.Size([1, 192, 3, 3]) conv_net = nn.Sequential( # 以下のように略記. # H: image height, W: image width # P: padding, KH: kernel height, KW: kernel weight # SH: stride height, SW: stride weight # in: dimension 3, out: dimension 32. # 111 = {(H)224 + 2 * (P)0 - (KH)4} / (SH)2 + 1 nn.Conv2d(3, 32, 4, stride=2), # 37 = 111 / (KH)3 nn.MaxPool2d(3), nn.ReLU(), # in: dimension 32. nn.BatchNorm2d(32), # in: dimension 32, out: dimension 96. # 18 = {(H)37 + 2 * (P)0 - (KH)3} / (SH)2 + 1 nn.Conv2d(32, 96, 3, stride=2), # 9 = 18 / (KH)2 nn.MaxPool2d(2), nn.ReLU(), # in: dimension 96. nn.BatchNorm2d(96), # in: dimension 96, out: dimension 192. # 6 = {(H)9 + 2 * (P)0 - (KH)4} / (SH)1 + 1 nn.Conv2d(96, 192, 4), # 3 = 6 / (KH)2 nn.MaxPool2d(2), nn.ReLU(), # in: dimension 192. nn.BatchNorm2d(192), # torch.Size([1, 192, 3, 3]) FlattenLayer() ) ~(略)~ # 8. execute training start = time.time() net.to("cuda:0") correct_list, wrong_list, correct_count, wrong_count = train_net(net, train_loader, test_loader, only_fc = False, n_iter = 10, device = "cuda:0") # 9. display processing time. end = time.time() images, labels = next(iter(test_loader)) fig = plt.figure(figsize=(12, 12)) print('--- display 9 wrong answers ------------------------------------------') print('wrong answers: ' + str(wrong_count) + ' count') # wrong_list[0][0:9][0]: <class 'list'>, wrong_list[0][0:9][0][1]: <class 'torch.Tensor'> print(wrong_list[0][0:9]) indexes_for_wrong_list_image = [x[0] for x in wrong_list[0][0:9]] print(str(indexes_for_wrong_list_image)) # ex. [30, 31, 32, 33, 34, 35, 36, 37, 38] wrong_images_list = [] for i, v in enumerate(images): if i in indexes_for_wrong_list_image: # print(i) # 検証用画像 の サイズ(224 × 224) # v[0].size(): torch.Size([224, 224]) # print(v[0].size()) # Adding a dimension to a tensor in PyTorch. # http://blog.outcome.io/adding-a-dimension-to-a-tensor-in-pytorch/ # uv: torch.Size([224, 224]) -> torch.Size([1, 224, 224]) uv = v[0][None, :, :] # print(uv.shape) wrong_images_list.append(uv) # How to turn a list of tensor to tensor? # https://discuss.pytorch.org/t/how-to-turn-a-list-of-tensor-to-tensor/8868/4 # -> convert list to torch.Tensor by torch.stack. wrong_images_list = torch.stack(wrong_images_list) print(wrong_images_list.size()) # torch.Size([9, 1, 224, 224]) wrong_images = torchvision.utils.make_grid(wrong_images_list, nrow=3, padding=1) plt.subplot(121) plt.title('wrong') imshow(wrong_images) print('--- display 9 correct answers ----------------------------------------') print('correct answers: ' + str(correct_count) + ' count') print(correct_list[0][0:9]) indexes_for_correct_list_image = [x[0] for x in correct_list[0][0:9]] print(str(indexes_for_correct_list_image)) # ex. [0, 1, 2, 3, 4, 5, 6, 7, 8] correct_images_list = [] for i, v in enumerate(images): if i in indexes_for_correct_list_image: uv = v[0][None, :, :] # print(uv.shape) correct_images_list.append(uv) correct_images_list = torch.stack(correct_images_list) print(correct_images_list.size()) # torch.Size([9, 1, 224, 224]) correct_images = torchvision.utils.make_grid(correct_images_list, nrow=3, padding=1) plt.subplot(122) plt.title('correct') imshow(correct_images) print('--------------------------------------------------') print('Elapsed Time: ' + str(end - start) + "[sec]") |
■実行結果(自作CNNモデル, batch size = 64, epoch = 10).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
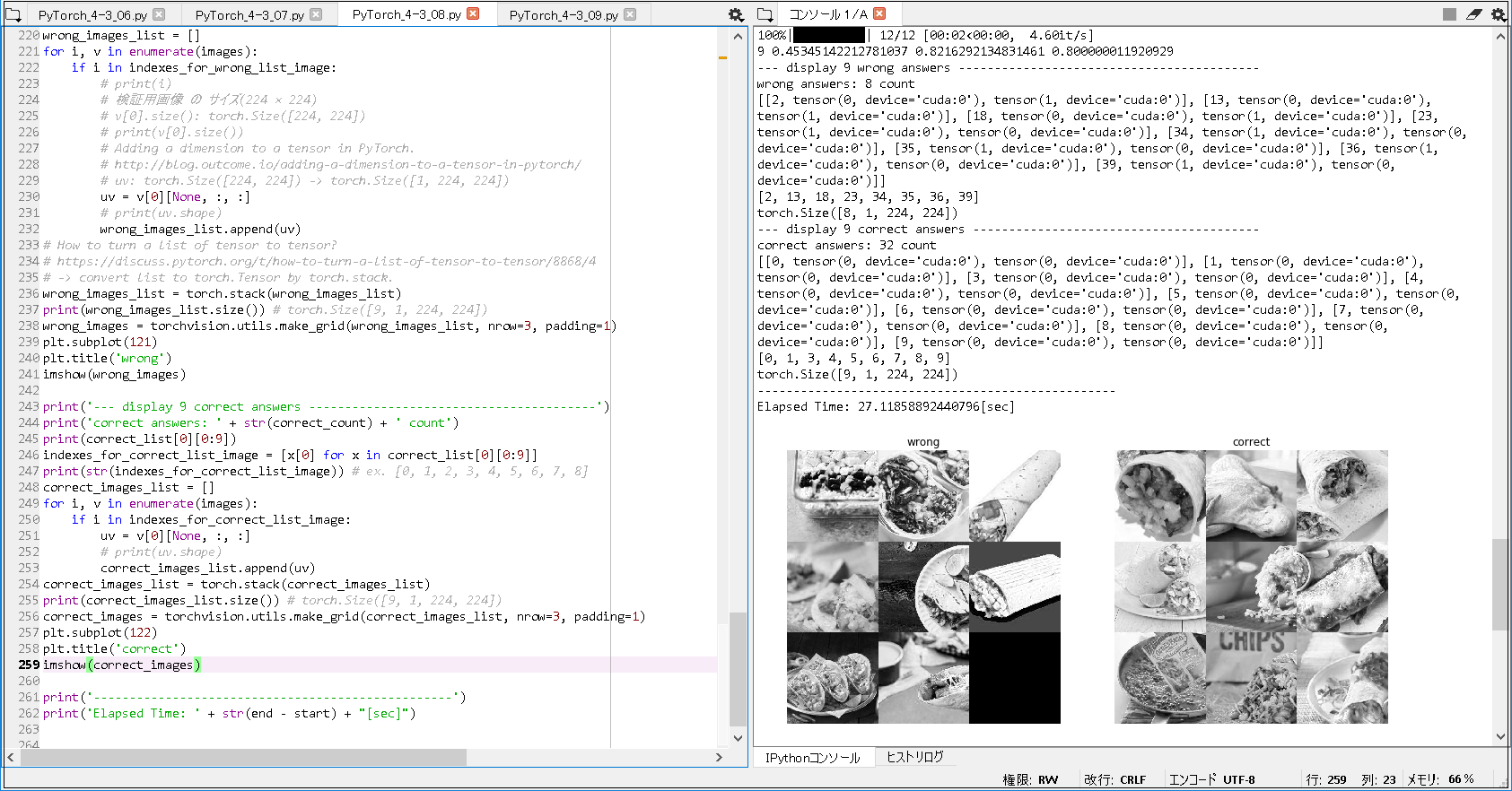
['burrito', 'taco'] -------------------------------------------------- {'burrito': 0, 'taco': 1} -------------------------------------------------- 100%|██████████| 12/12 [00:02<00:00, 4.52it/s] 0 0.6830520169301466 0.6362359550561798 0.5 100%|██████████| 12/12 [00:02<00:00, 4.77it/s] 1 0.6677237559448589 0.7078651685393258 0.5 100%|██████████| 12/12 [00:02<00:00, 4.83it/s] 2 0.5626629401337017 0.7443820224719101 0.5250000357627869 100%|██████████| 12/12 [00:02<00:00, 4.66it/s] 3 0.5950394137339159 0.7303370786516854 0.6000000238418579 100%|██████████| 12/12 [00:02<00:00, 4.80it/s] 4 0.536611795425415 0.7528089887640449 0.699999988079071 100%|██████████| 12/12 [00:02<00:00, 4.89it/s] 5 0.49385149641470477 0.7682584269662921 0.824999988079071 100%|██████████| 12/12 [00:02<00:00, 4.60it/s] 6 0.5017545900561593 0.7808988764044944 0.675000011920929 100%|██████████| 12/12 [00:02<00:00, 4.66it/s] 7 0.5005106126720255 0.7710674157303371 0.75 100%|██████████| 12/12 [00:02<00:00, 4.89it/s] 8 0.45471032099290326 0.7837078651685393 0.824999988079071 100%|██████████| 12/12 [00:02<00:00, 4.60it/s] 9 0.45345142212781037 0.8216292134831461 0.800000011920929 --- display 9 wrong answers ------------------------------------------ wrong answers: 8 count [[2, tensor(0, device='cuda:0'), tensor(1, device='cuda:0')], [13, tensor(0, device='cuda:0'), tensor(1, device='cuda:0')], [18, tensor(0, device='cuda:0'), tensor(1, device='cuda:0')], [23, tensor(1, device='cuda:0'), tensor(0, device='cuda:0')], [34, tensor(1, device='cuda:0'), tensor(0, device='cuda:0')], [35, tensor(1, device='cuda:0'), tensor(0, device='cuda:0')], [36, tensor(1, device='cuda:0'), tensor(0, device='cuda:0')], [39, tensor(1, device='cuda:0'), tensor(0, device='cuda:0')]] [2, 13, 18, 23, 34, 35, 36, 39] torch.Size([8, 1, 224, 224]) --- display 9 correct answers ---------------------------------------- correct answers: 32 count [[0, tensor(0, device='cuda:0'), tensor(0, device='cuda:0')], [1, tensor(0, device='cuda:0'), tensor(0, device='cuda:0')], [3, tensor(0, device='cuda:0'), tensor(0, device='cuda:0')], [4, tensor(0, device='cuda:0'), tensor(0, device='cuda:0')], [5, tensor(0, device='cuda:0'), tensor(0, device='cuda:0')], [6, tensor(0, device='cuda:0'), tensor(0, device='cuda:0')], [7, tensor(0, device='cuda:0'), tensor(0, device='cuda:0')], [8, tensor(0, device='cuda:0'), tensor(0, device='cuda:0')], [9, tensor(0, device='cuda:0'), tensor(0, device='cuda:0')]] [0, 1, 3, 4, 5, 6, 7, 8, 9] torch.Size([9, 1, 224, 224]) -------------------------------------------------- Elapsed Time: 27.11858892440796[sec] |
■転移学習(書籍CNNモデル).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 |
# -*- coding: utf-8 -*- # 1. library import. from __future__ import print_function import torch import torchvision from torch import nn, optim from torch.utils.data import DataLoader from torchvision.datasets import ImageFolder from torchvision import transforms from tqdm import tqdm import numpy as np import matplotlib.pyplot as plt import time # 2. display image function. # TRANSFER LEARNING TUTORIAL # https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html def imshow(inp, title=None): """Imshow for Tensor.""" inp = inp.numpy().transpose((1, 2, 0)) # mean = np.array([0.485, 0.456, 0.406]) # std = np.array([0.229, 0.224, 0.225]) # inp = std * inp + mean # inp = np.clip(inp, 0, 1) plt.axis('off') plt.imshow(inp) if title is not None: plt.title(title) # plt.pause(0.001) # pause a bit so that plots are updated # 3. describe the model training function. def eval_net(net, data_loader, device="cpu"): ~(略)~ # calculate prediction accuracy. acc = (ys == ypreds).float().sum() / len(ys) # a = [1, 2, 3, 4, 5] # b = [1, 3, 4, 3, 5] # c = [i for i, j in zip(a, b) if i == j] # print(c) # [1, 5] # [index, i, j] は, 画像のindex, 正解ラベル, 予測ラベル の意味. correct, wrong = [], [] for index, (i, j) in enumerate(zip(ys, ypreds)): if i == j: correct.append([index, i, j]) else: wrong.append([index, i, j]) return acc.item(), correct, wrong, len(correct), len(wrong) def train_net(net, train_loader, test_loader, only_fc= True, optimizer_cls = optim.Adam, loss_fn = nn.CrossEntropyLoss(), n_iter = 10, device = "cpu"): ~(略)~ correct_list, wrong_list = [], [] for epoch in range(n_iter): ~(略)~ e = eval_net(net, test_loader, device) val_acc.append(e[0]) if epoch + 1 == n_iter: correct_list.append(e[1]) wrong_list.append(e[2]) print(epoch, train_losses[-1], train_acc[-1], val_acc[-1], flush=True) return correct_list, wrong_list, e[3], e[4] ~(略)~ # 5. Create DataLoader with a batch size of 128 respectively. train_loader = DataLoader(train_imgs, batch_size=32, shuffle=True) test_loader = DataLoader(test_imgs, batch_size=32, shuffle=False) # https://github.com/andreh7/ecal-rechits-pytorch-training/blob/master/FlattenLayer.py class FlattenLayer(nn.Module): # a 'View' reshaping the input to dimension (minibatch, product of remaining dimensions) # typically to be used after a convolutional network and before the dense layers ### def __init__(self): ### super(FlattenLayer, self).__init__() def forward(self, x): # see e.g. https://github.com/pytorch/vision/blob/master/torchvision/models/alexnet.py#L44 # https://pytorch.org/docs/stable/tensors.html # the size -1 is inferred from other dimensions # print(x.size()) # torch.Size([1, 128, 24, 24]) return x.view(x.size(0), -1) def __repr__(self): return self.__class__.__name__ + " ()" # 定番のConvolutional Neural Networkをゼロから理解する. # https://deepage.net/deep_learning/2016/11/07/convolutional_neural_network.html # in: torch.Size([1, 3, 224, 224]) # out: torch.Size([1, 128, 24, 24]) conv_net = nn.Sequential( # 以下のように略記. # H: image height, W: image width # P: padding, KH: kernel height, KW: kernel weight # SH: stride height, SW: stride weight # in: dimension 3, out: dimension 32. # 220 = {(H)224 + 2 * (P)0 - (KH)5} / (SH)1 + 1 nn.Conv2d(3, 32, 5), # 110 = 220 / (KH)2 nn.MaxPool2d(2), nn.ReLU(), # in: dimension 32. nn.BatchNorm2d(32), # in: dimension 32, out: dimension 64. # 106 = {(H)110 + 2 * (P)0 - (KH)5} / (SH)1 + 1 nn.Conv2d(32, 64, 5), # 53 = 106 / (KH)2 nn.MaxPool2d(2), nn.ReLU(), # in: dimension 64. nn.BatchNorm2d(64), # in: dimension 64, out: dimension 128. # 49 = {(H)53 + 2 * (P)0 - (KH)5} / (SH)1 + 1 nn.Conv2d(64, 128, 5), # 24 = 49 / (KH)2 nn.MaxPool2d(2), nn.ReLU(), # in: dimension 128. nn.BatchNorm2d(128), # torch.Size([1, 128, 24, 24]) FlattenLayer() ) ~(略)~ # 8. execute training start = time.time() net.to("cuda:0") correct_list, wrong_list, correct_count, wrong_count = train_net(net, train_loader, test_loader, only_fc = False, n_iter = 10, device = "cuda:0") # 9. display processing time. end = time.time() images, labels = next(iter(test_loader)) fig = plt.figure(figsize=(12, 12)) print('--- display 9 wrong answers ------------------------------------------') print('wrong answers: ' + str(wrong_count) + ' count') # wrong_list[0][0:9][0]: <class 'list'>, wrong_list[0][0:9][0][1]: <class 'torch.Tensor'> print(wrong_list[0][0:9]) indexes_for_wrong_list_image = [x[0] for x in wrong_list[0][0:9]] print(str(indexes_for_wrong_list_image)) # ex. [30, 31, 32, 33, 34, 35, 36, 37, 38] wrong_images_list = [] for i, v in enumerate(images): if i in indexes_for_wrong_list_image: # print(i) # 検証用画像 の サイズ(224 × 224) # v[0].size(): torch.Size([224, 224]) # print(v[0].size()) # Adding a dimension to a tensor in PyTorch. # http://blog.outcome.io/adding-a-dimension-to-a-tensor-in-pytorch/ # uv: torch.Size([224, 224]) -> torch.Size([1, 224, 224]) uv = v[0][None, :, :] # print(uv.shape) wrong_images_list.append(uv) # How to turn a list of tensor to tensor? # https://discuss.pytorch.org/t/how-to-turn-a-list-of-tensor-to-tensor/8868/4 # -> convert list to torch.Tensor by torch.stack. wrong_images_list = torch.stack(wrong_images_list) print(wrong_images_list.size()) # torch.Size([9, 3, 224, 224]) wrong_images = torchvision.utils.make_grid(wrong_images_list, nrow=3, padding=1) plt.subplot(121) plt.title('wrong') imshow(wrong_images) print('--- display 9 correct answers ----------------------------------------') print('correct answers: ' + str(correct_count) + ' count') print(correct_list[0][0:9]) indexes_for_correct_list_image = [x[0] for x in correct_list[0][0:9]] print(str(indexes_for_correct_list_image)) # ex. [0, 1, 2, 3, 4, 5, 6, 7, 8] correct_images_list = [] for i, v in enumerate(images): if i in indexes_for_correct_list_image: uv = v[0][None, :, :] # print(uv.shape) correct_images_list.append(uv) correct_images_list = torch.stack(correct_images_list) print(correct_images_list.size()) # torch.Size([9, 3, 224, 224]) correct_images = torchvision.utils.make_grid(correct_images_list, nrow=3, padding=1) plt.subplot(122) plt.title('correct') imshow(correct_images) print('--------------------------------------------------') print('Elapsed Time: ' + str(end - start) + "[sec]") |
■実行結果(書籍CNNモデル, batch size = 32, epoch = 10).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
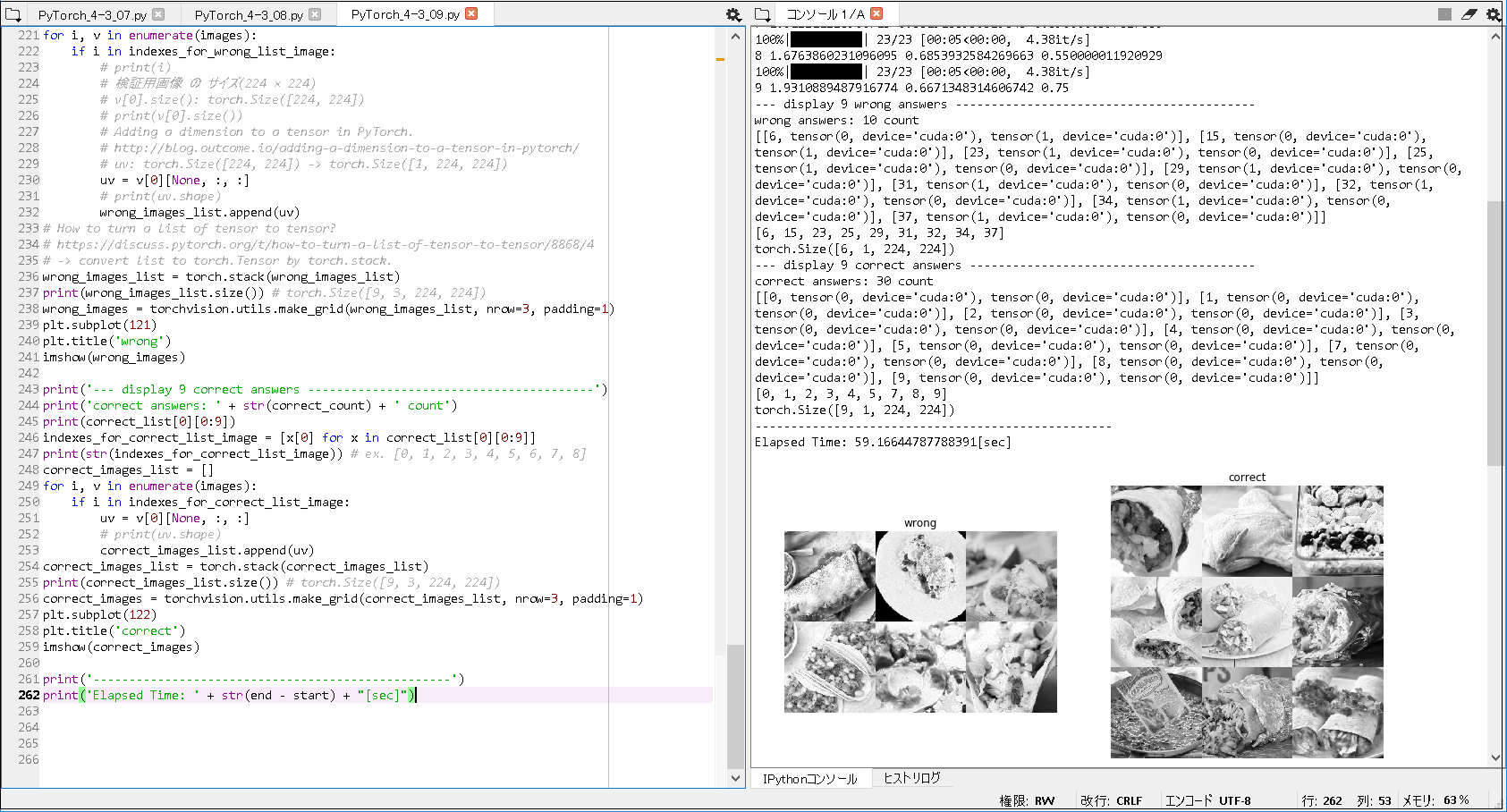
['burrito', 'taco'] -------------------------------------------------- {'burrito': 0, 'taco': 1} -------------------------------------------------- 100%|██████████| 23/23 [00:07<00:00, 4.46it/s] 0 2.479653466831554 0.5435393258426966 0.5 100%|██████████| 23/23 [00:05<00:00, 4.10it/s] 1 2.466307753866369 0.5814606741573034 0.6000000238418579 100%|██████████| 23/23 [00:05<00:00, 4.19it/s] 2 2.526581260291013 0.6151685393258427 0.6000000238418579 100%|██████████| 23/23 [00:05<00:00, 4.90it/s] 3 2.122632611881603 0.6587078651685393 0.6000000238418579 100%|██████████| 23/23 [00:05<00:00, 4.33it/s] 4 2.096345370466059 0.6320224719101124 0.6000000238418579 100%|██████████| 23/23 [00:05<00:00, 4.48it/s] 5 2.1521816036917945 0.6432584269662921 0.7250000238418579 100%|██████████| 23/23 [00:05<00:00, 4.36it/s] 6 2.21564337069338 0.625 0.6500000357627869 100%|██████████| 23/23 [00:05<00:00, 4.40it/s] 7 1.912211228500713 0.6615168539325843 0.6500000357627869 100%|██████████| 23/23 [00:05<00:00, 4.38it/s] 8 1.6763860231096095 0.6853932584269663 0.550000011920929 100%|██████████| 23/23 [00:05<00:00, 4.38it/s] 9 1.9310889487916774 0.6671348314606742 0.75 --- display 9 wrong answers ------------------------------------------ wrong answers: 10 count [[6, tensor(0, device='cuda:0'), tensor(1, device='cuda:0')], [15, tensor(0, device='cuda:0'), tensor(1, device='cuda:0')], [23, tensor(1, device='cuda:0'), tensor(0, device='cuda:0')], [25, tensor(1, device='cuda:0'), tensor(0, device='cuda:0')], [29, tensor(1, device='cuda:0'), tensor(0, device='cuda:0')], [31, tensor(1, device='cuda:0'), tensor(0, device='cuda:0')], [32, tensor(1, device='cuda:0'), tensor(0, device='cuda:0')], [34, tensor(1, device='cuda:0'), tensor(0, device='cuda:0')], [37, tensor(1, device='cuda:0'), tensor(0, device='cuda:0')]] [6, 15, 23, 25, 29, 31, 32, 34, 37] torch.Size([6, 1, 224, 224]) --- display 9 correct answers ---------------------------------------- correct answers: 30 count [[0, tensor(0, device='cuda:0'), tensor(0, device='cuda:0')], [1, tensor(0, device='cuda:0'), tensor(0, device='cuda:0')], [2, tensor(0, device='cuda:0'), tensor(0, device='cuda:0')], [3, tensor(0, device='cuda:0'), tensor(0, device='cuda:0')], [4, tensor(0, device='cuda:0'), tensor(0, device='cuda:0')], [5, tensor(0, device='cuda:0'), tensor(0, device='cuda:0')], [7, tensor(0, device='cuda:0'), tensor(0, device='cuda:0')], [8, tensor(0, device='cuda:0'), tensor(0, device='cuda:0')], [9, tensor(0, device='cuda:0'), tensor(0, device='cuda:0')]] [0, 1, 2, 3, 4, 5, 7, 8, 9] torch.Size([9, 1, 224, 224]) -------------------------------------------------- Elapsed Time: 59.16644787788391[sec] |
■以上の実行結果から, 以下のことが分かった.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
① GPUメモリに関するエラー(RuntimeError: CUDA error: out of memory). 自作CNNモデルで, バッチサイズを, 64に設定して, 3~4回実行してすると, 上記のようなエラーメッセージが出力された. 書籍CNNモデルでは, バッチサイズを, 64 に設定して実行すると, 上記エラーが出力されて動かせなかったので, 書籍通りに, バッチサイズ 32 で動作確認した. ② 出力画像に関すること. ・テスト画像は, 合計40枚(burrito: 20枚, taco: 20枚)で確認している. ・自作CNNモデルで, wrong の 一番右下が, 黒い正方形で出力されたが, 不正解だったテスト画像が, 8枚だったため, 9枚に満たなかったことによる出力結果と理解している. ・書籍CNNモデルで, wrong が, 6枚しか表示されてない理由として, バッチサイズ を 32 に設定したことによる出力結果([6, 15, 23, 25, 29, 31] の 6枚)と理解している. ③ 自作CNNモデルで, の テスト画像 の (index的に)39番目 について, 'burrito' と 予想(tensor(0, device='cuda:0')) したが, 'taco' が 正解(tensor(1, device='cuda:0')) との情報が得られた. ④ 書籍CNNモデルで, の テスト画像 の (index的に)6番目 について, 'taco' と 予想(tensor(1, device='cuda:0')) したが, 'burrito' が 正解(tensor(0, device='cuda:0')) との情報が得られた. ⑤ 転移学習の精度 と 正解数 との関係. 転移学習の精度が上がると, テスト画像の正解数が上がると予想される. ※直観的には, 正しく見えるが, 具体的なデータとして確認することが出来た. [自作CNNモデル] 転移学習の精度: 約82% テスト画像正解数: 40枚中, 32枚正解. [書籍CNNモデル] 転移学習の精度: 約66% テスト画像正解数: 40枚中, 30枚正解. ⑥ 転移学習の成否について. 自作CNNモデル, 書籍CNNモデルのいずれも, 何度も実行していると, 転移学習が上手くいかない場合が出てくる(体感として, 2割前後)ことがあったので, 技術的な今後の動向に着目したい. |
■参照サイト
【参照URL①】定番のConvolutional Neural Networkをゼロから理解する.
【参照URL②】Adding a dimension to a tensor in PyTorch.
【参照URL③】How to turn a list of tensor to tensor?
【参照URL④】andreh7/ecal-rechits-pytorch-training
【参照URL⑤】TRANSFER LEARNING TUTORIAL
■参考書籍
現場で使える! PyTorch開発入門 深層学習モデルの作成とアプリケーションへの実装 (AI & TECHNOLOGY)