
1. 環境は、Window 10 Home (64bit) 上で行った。
2. Anaconda3 (64bit) – Spyder上で、動作確認を行った。
3. python の バージョンは、python 3.7.0 である。
4. pytorch の バージョンは、pytorch 0.4.1 である。
5. GPU は, NVIDIA社 の GeForce GTX 1050 である。
6. CPU は, Intel社 の Core(TM) i7-7700HQ である。
今回確認した内容は、現場で使える! PyTorch開発入門 深層学習モデルの作成とアプリケーションへの実装 (AI & TECHNOLOGY) の 6.2 ニューラル行列因子分解 (P.160 – P.169) である。
※プログラムの詳細は, 書籍を参考(P.160 – P.169)にして下さい.
■ニューラル行列因子分解の訓練に関する動作確認(書籍から一部抜粋・追記).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
# -*- coding: utf-8 -*- # 1. library import. from __future__ import print_function import csv from sklearn.feature_extraction.text import CountVectorizer import torch from torch import nn, optim from torch.utils.data import (Dataset, DataLoader) import os, time import pandas as pd from sklearn import model_selection from tqdm import tqdm from statistics import mean # 2. get csv data. # downloaded from the site below. # MovieLens # https://grouplens.org/datasets/movielens/ start = time.time() folder_path = os.path.expanduser('~') folder_path = folder_path + '\\.spyder-py3\\pytorch\\ml-20m\\' # X is a pair of userId, movieId. df = pd.read_csv(folder_path + 'ratings.csv', encoding = 'utf-8') ~(略)~ for epoch in range(6): ~(略)~ net.eval() test_score = eval_net(net, test_loader, device = "cuda:0") print(epoch, mean(loss_log), test_score, flush = True) # save the learning result every ten iterations. # SAVING AND LOADING MODELS # https://pytorch.org/tutorials/beginner/saving_loading_models.html # -> A common PyTorch convention is # to save models using either a .pt or .pth file extension. torch.save(net.state_dict(), folder_path + "nmf_{:03d}.pth".format(epoch), pickle_protocol = 4) # 10. display processing time. end = time.time() print('--------------------------------------------------') print('Elapsed Time: ' + str(end - start) + "[sec]") |
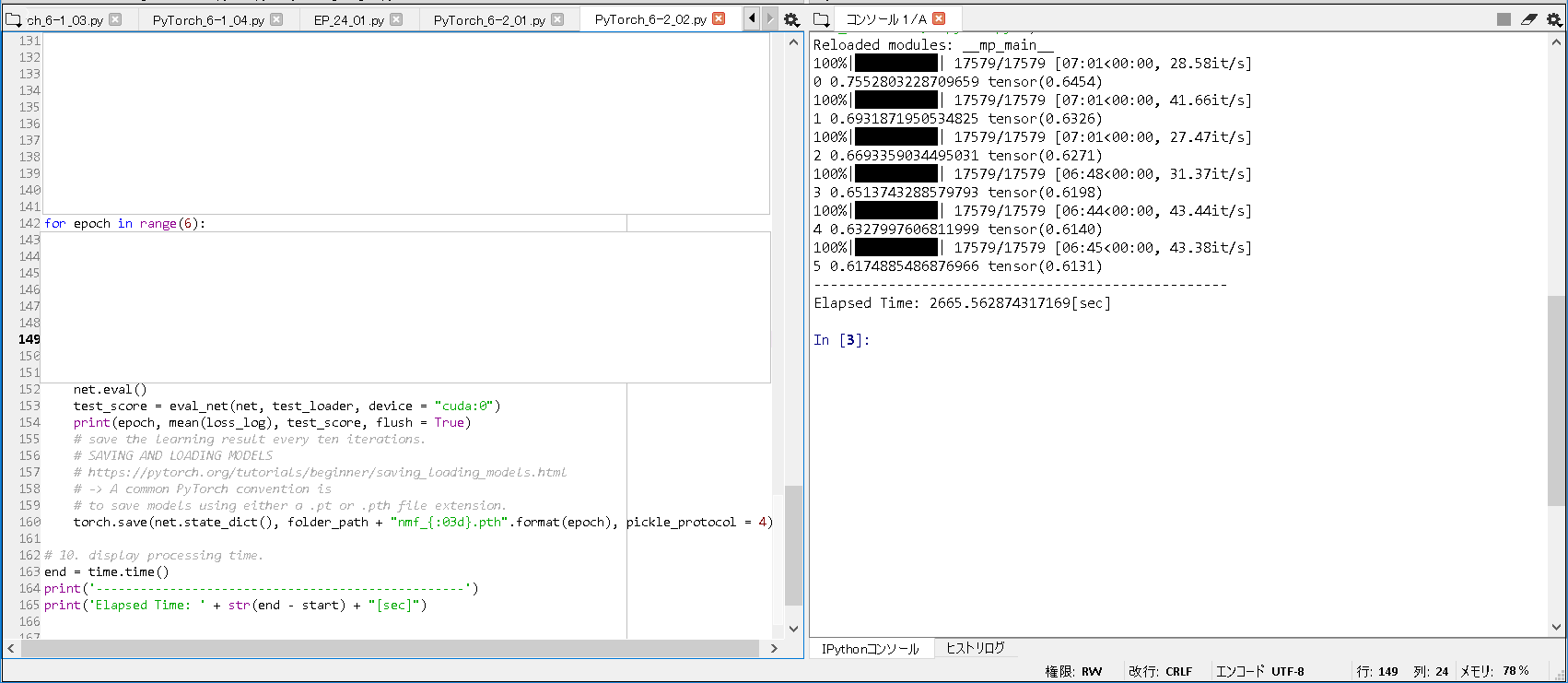
■実行結果(epoch 5).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Reloaded modules: __mp_main__ 100%|██████████| 17579/17579 [07:01<00:00, 28.58it/s] 0 0.7552803228709659 tensor(0.6454) 100%|██████████| 17579/17579 [07:01<00:00, 41.66it/s] 1 0.6931871950534825 tensor(0.6326) 100%|██████████| 17579/17579 [07:01<00:00, 27.47it/s] 2 0.6693359034495031 tensor(0.6271) 100%|██████████| 17579/17579 [06:48<00:00, 31.37it/s] 3 0.6513743288579793 tensor(0.6198) 100%|██████████| 17579/17579 [06:44<00:00, 43.44it/s] 4 0.6327997606811999 tensor(0.6140) 100%|██████████| 17579/17579 [06:45<00:00, 43.38it/s] 5 0.6174885486876966 tensor(0.6131) -------------------------------------------------- Elapsed Time: 2665.562874317169[sec] |
■指定ユーザの映画評価に関する予測についての動作確認(書籍から一部抜粋・追記).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
# -*- coding: utf-8 -*- # 1. library import. from __future__ import print_function import csv from sklearn.feature_extraction.text import CountVectorizer import torch from torch import nn import os, time import pandas as pd # 2. get csv data. # downloaded from the site below. # MovieLens # https://grouplens.org/datasets/movielens/ start = time.time() folder_path = os.path.expanduser('~') folder_path = folder_path + '\\.spyder-py3\\pytorch\\ml-20m\\' # X is a pair of userId, movieId. df = pd.read_csv(folder_path + 'ratings.csv', encoding = 'utf-8') ~(略)~ print('- cv.get_feature_names() -------------------------------') print(cv.get_feature_names()) print() ~(略)~ # 7. load model. net.load_state_dict(torch.load(folder_path + "nmf_005.pth")) ~(略)~ query_genres = query_genres.to("cuda:0") query1 = query1.to("cuda:0") query100 = query100.to("cuda:0") query10000 = query10000.to("cuda:0") # RuntimeError: Expected object of type torch.LongTensor # but found type torch.cuda.LongTensor for argument #3 'index' # -> net.to("cuda:0") を追加. net.to("cuda:0") nq1 = net(query1, query_genres) nq100 = net(query100, query_genres) nq10000 = net(query10000, query_genres) print('- userId = 1 -------------------------------------------') print(nq1) print('- userId = 100 -----------------------------------------') print(nq100) print('- userId = 10000 ---------------------------------------') print(nq10000) # 9. display processing time. end = time.time() print('--------------------------------------------------------') print('Elapsed Time: ' + str(end - start) + "[sec]") |
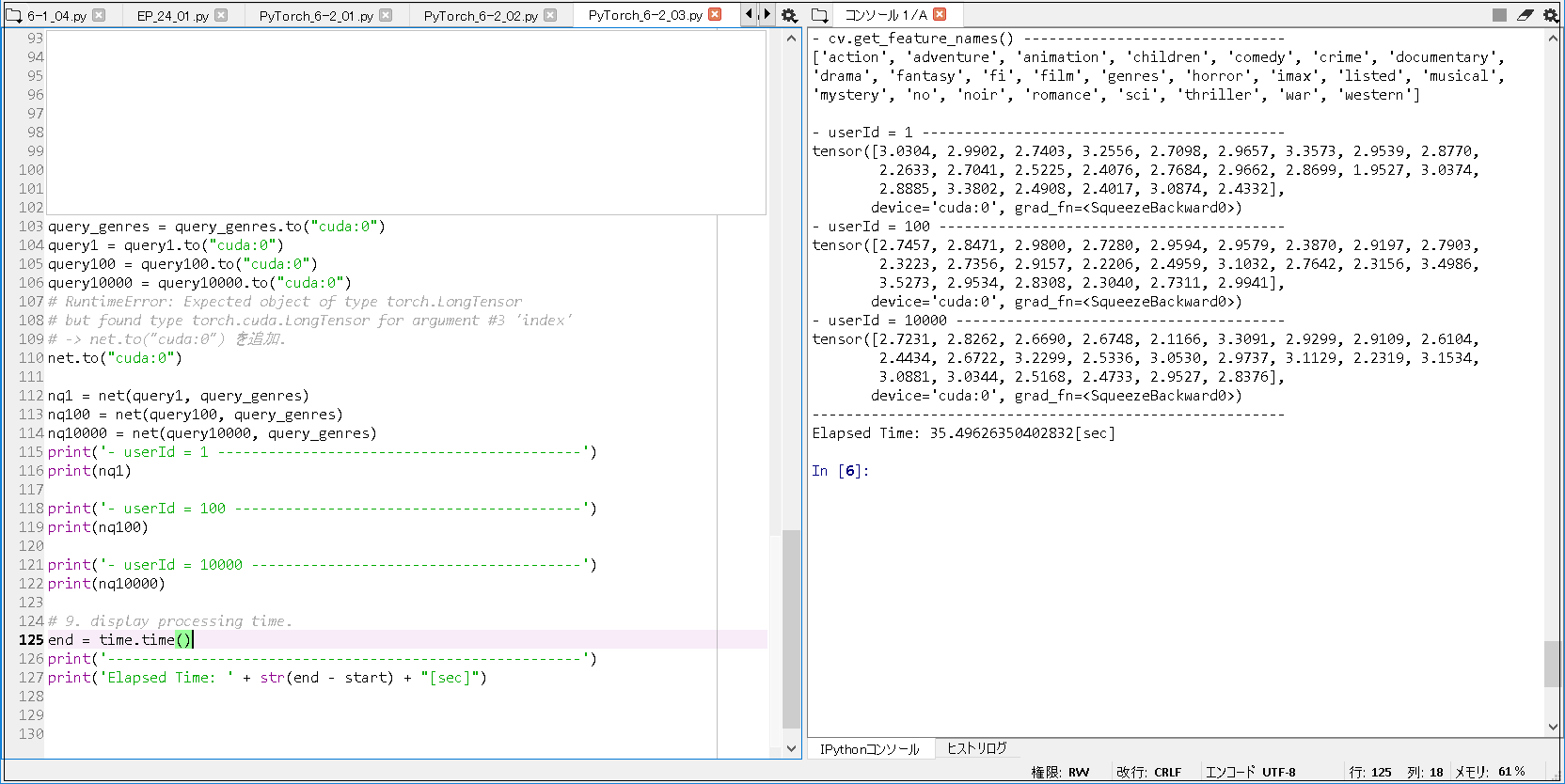
■実行結果.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
- cv.get_feature_names() ------------------------------- ['action', 'adventure', 'animation', 'children', 'comedy', 'crime', 'documentary', 'drama', 'fantasy', 'fi', 'film', 'genres', 'horror', 'imax', 'listed', 'musical', 'mystery', 'no', 'noir', 'romance', 'sci', 'thriller', 'war', 'western'] - userId = 1 ------------------------------------------- tensor([3.0304, 2.9902, 2.7403, 3.2556, 2.7098, 2.9657, 3.3573, 2.9539, 2.8770, 2.2633, 2.7041, 2.5225, 2.4076, 2.7684, 2.9662, 2.8699, 1.9527, 3.0374, 2.8885, 3.3802, 2.4908, 2.4017, 3.0874, 2.4332], device='cuda:0', grad_fn=<SqueezeBackward0>) - userId = 100 ----------------------------------------- tensor([2.7457, 2.8471, 2.9800, 2.7280, 2.9594, 2.9579, 2.3870, 2.9197, 2.7903, 2.3223, 2.7356, 2.9157, 2.2206, 2.4959, 3.1032, 2.7642, 2.3156, 3.4986, 3.5273, 2.9534, 2.8308, 2.3040, 2.7311, 2.9941], device='cuda:0', grad_fn=<SqueezeBackward0>) - userId = 10000 --------------------------------------- tensor([2.7231, 2.8262, 2.6690, 2.6748, 2.1166, 3.3091, 2.9299, 2.9109, 2.6104, 2.4434, 2.6722, 3.2299, 2.5336, 3.0530, 2.9737, 3.1129, 2.2319, 3.1534, 3.0881, 3.0344, 2.5168, 2.4733, 2.9527, 2.8376], device='cuda:0', grad_fn=<SqueezeBackward0>) -------------------------------------------------------- Elapsed Time: 35.49626350402832[sec] |
■以上の実行結果から, 以下のことが分かった.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
1. MAEの確認. epoch 5 で, 約0.62 まで改善した(※書籍とほぼ同じ結果). 2. ニューラル行列因子分解の訓練. epoch 5 で, 約2665秒 かかった. 3. 指定ユーザ(userId) の 映画ジャンル(action, adventure,...) に対するスコアについて. ・userId = 1 の 場合: -> ロマンス映画(romance) で, スコアが, 最大(3.3802) と分かる. ・userId = 100 の 場合: -> ホラー映画(horror) で, スコアが, 最小(2.2206) と分かる. ・userId = 10000 の 場合: -> ファンタジー映画(fantasy) で, スコアが, 2.6104 と分かる. |
■参照サイト
【参照URL①】MovieLens
【参照URL②】SAVING AND LOADING MODELS
■参考書籍
現場で使える! PyTorch開発入門 深層学習モデルの作成とアプリケーションへの実装 (AI & TECHNOLOGY)