
1. 環境は、Window 10 Home (64bit) 上で行った。
2. Anaconda3 (64bit) – Spyder上で、動作確認を行った。
3. python の バージョンは、python 3.7.0 である。
4. pytorch の バージョンは、pytorch 0.4.1 である。
5. GPU は, NVIDIA社 の GeForce GTX 1050 である。
6. CPU は, Intel社 の Core(TM) i7-7700HQ である。
今回確認した内容は、現場で使える! PyTorch開発入門 深層学習モデルの作成とアプリケーションへの実装 (AI & TECHNOLOGY) の 5.5 Encoder-Decoderモデルによる機械翻訳 (P.135 – P.145) である。
※1. プログラムの詳細は, 書籍を参考(P.135 – P.145)にして下さい.
※2. 書籍上で紹介されていたスペイン語のパターン以外の言語も, とりあえず動かしてみた.
スペイン語: spa.txt
スウェーデン語: swe.txt
ドイツ語: deu.txt
フランス語: fra.txt
ロシア語: rus.txt
■Encoder-Decoderモデルの動作確認(書籍から一部抜粋・加筆).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
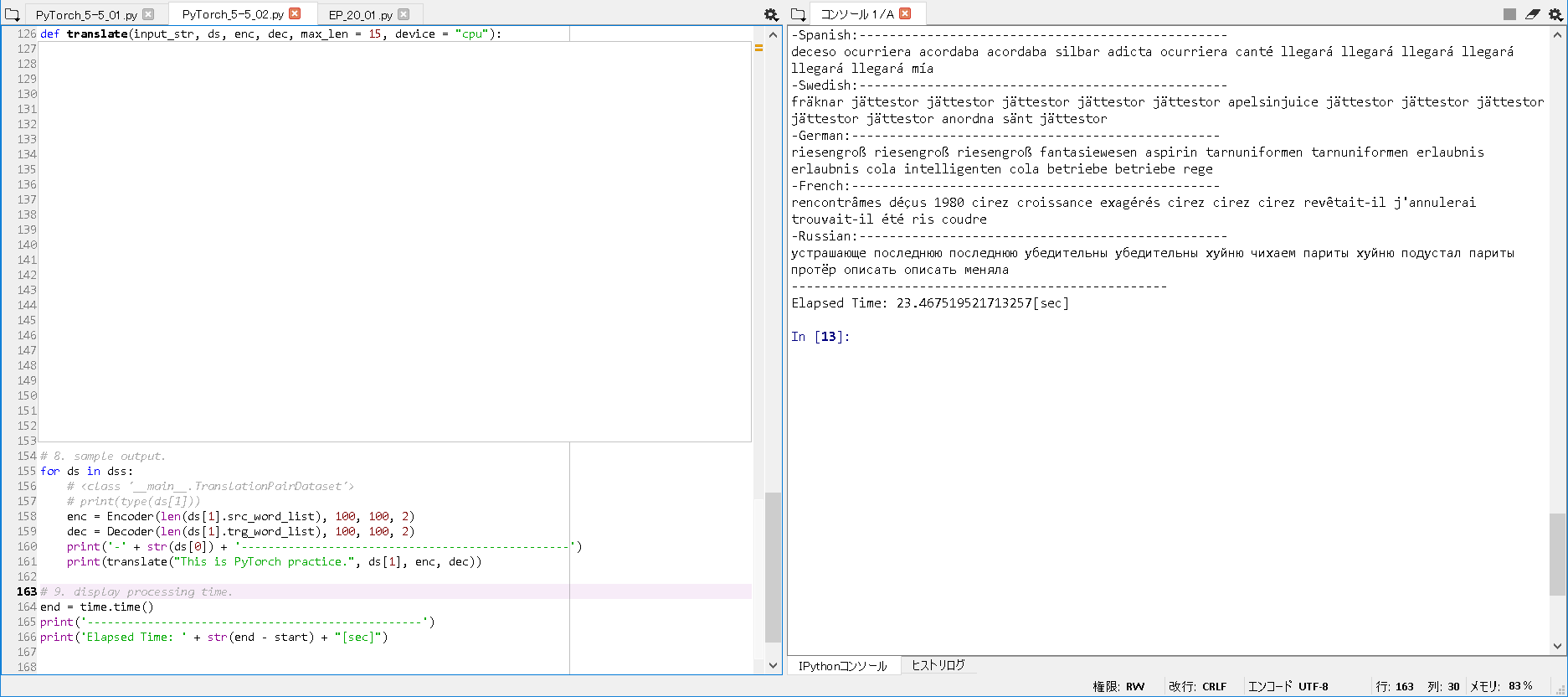
# -*- coding: utf-8 -*- # 1. library import. from __future__ import print_function import torch from torch import nn, optim from torch.utils.data import (Dataset, DataLoader) import os, re, time, collections, itertools ~(略)~ # 4. create Dataset Class. start = time.time() batch_size = 64 max_len = 10 folder_path = os.path.expanduser('~') folder_path = folder_path + '\\.spyder-py3\\pytorch\\translation\\' dss = [] dss.append(["Spanish:", TranslationPairDataset(folder_path + "\\spa.txt", max_len = max_len)]) dss.append(["Swedish:", TranslationPairDataset(folder_path + "\\swe.txt", max_len = max_len)]) dss.append(["German:", TranslationPairDataset(folder_path + "\\deu.txt", max_len = max_len)]) dss.append(["French:", TranslationPairDataset(folder_path + "\\fra.txt", max_len = max_len)]) dss.append(["Russian:", TranslationPairDataset(folder_path + "\\rus.txt", max_len = max_len)]) # loader = DataLoader(ds, batch_size = batch_size, shuffle = True, num_workers = 0) ~(略)~ # 7. declare functions to translate. def translate(input_str, ds, enc, dec, max_len = 15, device = "cpu"): ~(略)~ # 8. sample output. for ds in dss: # <class '__main__.TranslationPairDataset'> # print(type(ds[1])) enc = Encoder(len(ds[1].src_word_list), 100, 100, 2) dec = Decoder(len(ds[1].trg_word_list), 100, 100, 2) print('-' + str(ds[0]) + '-------------------------------------------------') print(translate("This is PyTorch practice.", ds[1], enc, dec)) # 9. display processing time. end = time.time() print('--------------------------------------------------') print('Elapsed Time: ' + str(end - start) + "[sec]") |
■実行結果.
書籍上で指摘されているが, とりあえず, よく分からない文章が生成された.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
-Spanish:------------------------------------------------- deceso ocurriera acordaba acordaba silbar adicta ocurriera canté llegará llegará llegará llegará llegará llegará mía -Swedish:------------------------------------------------- fräknar jättestor jättestor jättestor jättestor jättestor apelsinjuice jättestor jättestor jättestor jättestor jättestor anordna sänt jättestor -German:------------------------------------------------- riesengroß riesengroß riesengroß fantasiewesen aspirin tarnuniformen tarnuniformen erlaubnis erlaubnis cola intelligenten cola betriebe betriebe rege -French:------------------------------------------------- rencontrâmes déçus 1980 cirez croissance exagérés cirez cirez cirez revêtait-il j'annulerai trouvait-il été ris coudre -Russian:------------------------------------------------- устрашающе последнюю последнюю убедительны убедительны хуйню чихаем париты хуйню подустал париты протёр описать описать меняла -------------------------------------------------- Elapsed Time: 23.467519521713257[sec] |
■参照サイト
【参照URL①】Tab-delimited Bilingual Sentence Pairs
■参考書籍
現場で使える! PyTorch開発入門 深層学習モデルの作成とアプリケーションへの実装 (AI & TECHNOLOGY)