
Kaggle の仕組みに慣れるため, Digit Recognizer (Competition)に挑戦してみた.
■感想.
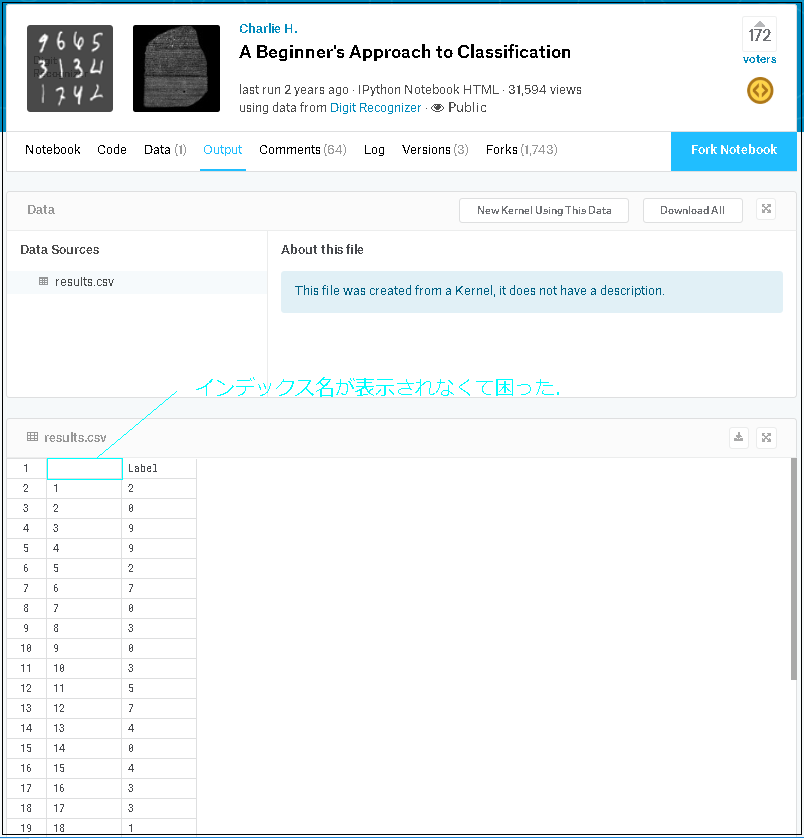
1. Kaggle の Kernels で, プログラム実行すると, CSVファイル(results.csv) に, インデックス名 ‘ImageId’ が出力されず, 苦戦した.
2. 一つのセルで, プログラム実行(CSV出力まで)すると, 1. の現象が起こるらしいことが確認できた.
-> CSVファイル出力に関するプログラムだけ, 別セルで実行したところ, 1. の現象が解消した(※Kaggle の Kernels の bugか?).
-> 下記, Python版(Kaggle)プログラムは, 二つのセルで実行する版を転記している(※1. の現象が改善された版)
3. ちなみに, Google Colaboratory 上では, 一つのセルで, プログラム実行(CSV出力まで)しても, 想定通り, インデックス名 ‘ImageId’ が出力され, 1. の現象は起きなかった.
詳細は, 本家のサイトDigit Recognizerをご覧下さい.
■Python版(Google Colaboratory)プログラム
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
# 1. import library. import pandas as pd import matplotlib.pyplot as plt, matplotlib.image as mpimg import numpy as np from sklearn.model_selection import train_test_split from sklearn import svm from google.colab import files # 2. Loading the data. # The prefix is abbreviated as follows. # Training data … a # Test data … b data = pd.read_csv("drive/Machine Learning/DigitRecognizer/train.csv") images = data.iloc[0:5000,1:] labels = data.iloc[0:5000,:1] aI, bI, aL, bL = train_test_split(images, labels, train_size=0.8, random_state=0) # 3. How did our model do? aI[aI > 0] = 1 bI[bI > 0] = 1 # 4. ReTraining our model. clf = svm.SVC() clf.fit(aI, aL.values.ravel()) # 5. Labelling the test data. tdata = pd.read_csv("drive/Machine Learning/DigitRecognizer/test.csv") tdata[tdata > 0] = 1 results = clf.predict(tdata[0:5000]) print(results) # 6. Create CSV file of output result. df = pd.DataFrame(results) df.index+=1 df.index.name='ImageId' df.columns=['Label'] df.to_csv('drive/Machine Learning/DigitRecognizer/results.csv', header=True) |
■Python版(Kaggle)プログラム
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 1. import library. import pandas as pd import matplotlib.pyplot as plt, matplotlib.image as mpimg import numpy as np from sklearn.model_selection import train_test_split from sklearn import svm # 2. Loading the data. # The prefix is abbreviated as follows. # Training data … a # Test data … b data = pd.read_csv("../input/train.csv") images = data.iloc[0:5000,1:] labels = data.iloc[0:5000,:1] aI, bI, aL, bL = train_test_split(images, labels, train_size=0.8, random_state=0) # 3. How did our model do? aI[aI > 0] = 1 bI[bI > 0] = 1 # 4. ReTraining our model. clf = svm.SVC() clf.fit(aI, aL.values.ravel()) # 5. Labelling the test data. tdata = pd.read_csv("../input/test.csv") tdata[tdata > 0] = 1 results = clf.predict(tdata[0:28000]) print(results) # [2 0 9 ... 1 7 3] |
|
1 2 3 4 5 6 7 8 |
# 6. Create CSV file of output result. # -> This program was executed in next cell, because to avoid a bug on kaggle kernels # which the index name is not output to the CSV file when executed together with the above program. df = pd.DataFrame(results) df.index+=1 df.index.name='ImageId' df.columns=['Label'] df.to_csv('results.csv', header=True) |
■ ■ ■ 提出手順(概要) ■ ■ ■
■エラー時
① CSVファイル確認(インデックス名が表示されなかった)
② 提出するためにボタン押下
③ CSVファイルアップロード、説明文追記など

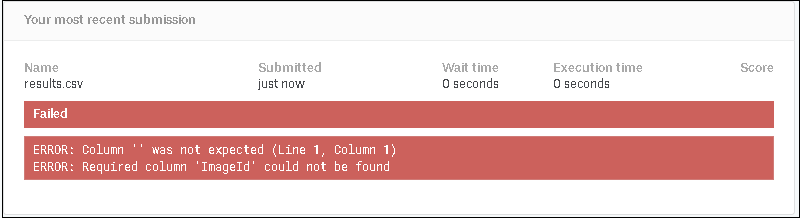
④ エラー表示を確認
■OK時
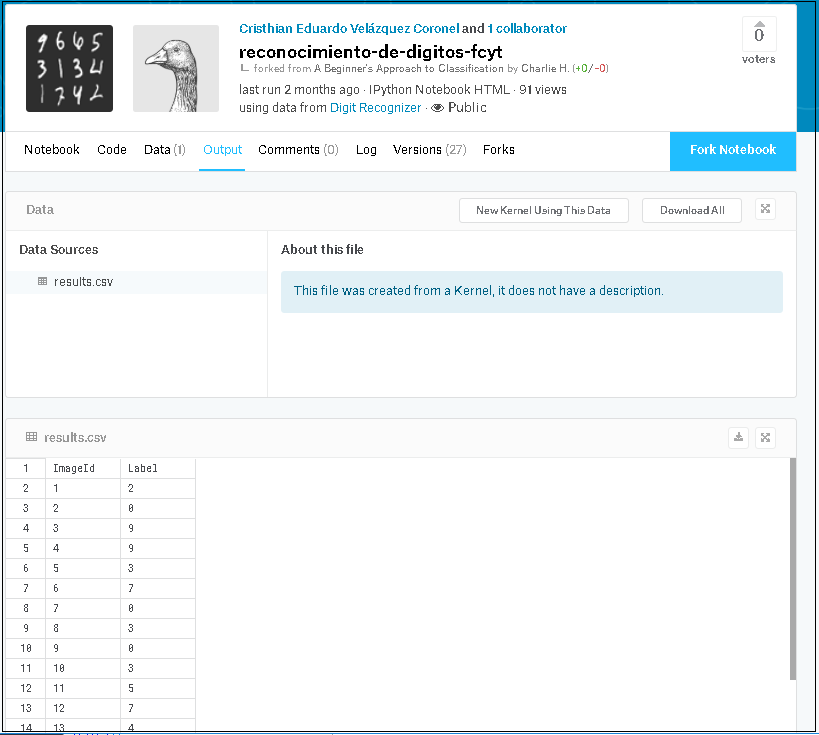
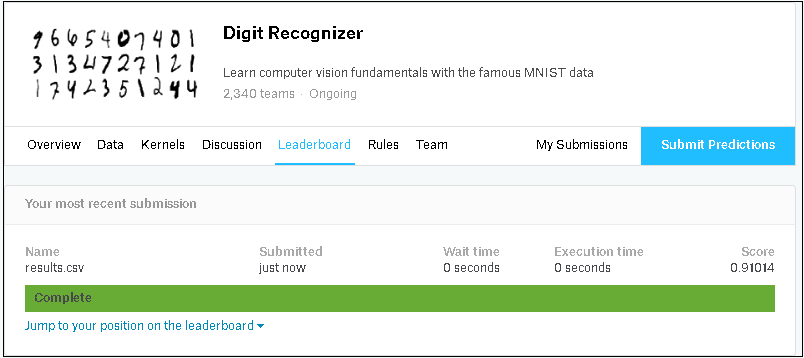
① CSVファイル確認(インデックス名 ‘ImageId’ が表示された)
② 提出するためにボタン押下
③ CSVファイルアップロード、説明文追記など

④ 提出完了(チュートリアル完了、Leaderboard に掲載されることも確認できた)
■参照サイト
Digit Recognizer